



维度语音情感识别研究综述
李海峰
,
陈婧
,
马琳
,
薄洪健
,
徐聪
,
李洪伟
软件学报  2020, Vol. 31 Issue (8): 2465-2491 2020, Vol. 31 Issue (8): 2465-2491 |


情感是人类智能的重要组成部分, 使计算机拥有情感、像人一样识别和表达情感, 仍是一个亟须解决的问题.Picard提出了情感计算的概念, 开辟了计算机科学的新领域.目前, 情感识别的研究主要集中在语音情感识别、基于人脸的情感识别、文本情感识别、肢体行为情感识别.语音是人类交流情感和思想的最自然、最有效的方式之一[1], 是人类生存和社会活动极其重要的信息传递和情感表达交流的方式.语音是人的发音器官发出的具有一定社会意义的声音, 是表示语言的声音符号, 不仅承载了语义信息, 而且包含与情感相关的声学信息, 如音高、响度、韵律、音色等[2].语音的情感信息包含在声学参数随时间的变化中, 如基频、能量、频谱、语调变化等[3-5].与基于人脸的情感识别相比, 语音信号具有时序性, 承载丰富的上下文信息.与文本相比, 语音可以通过声学属性改变情感强度.肢体行为情感交互涉及较多的心理学范畴, 表达情感时存在较大的模糊不确定性, 在特征提取与情感分类方面仍面临较大困难, 应用较少.
语音情感识别研究已有30余年的历史, 吸引了世界范围内的研究单位、学者们的重点研究.如美国MIT多媒体实验室以Picard教授带领的情感计算研究组(https://affect.media.mit.edu/), 研究方向包括多维信号建模、计算机视觉及模式识别、机器学习、人机交互和情感计算等.Picard的《Affective Computing》开创了计算机科学和人工智能学科的新分支——“情感计算”; 德国奥格斯堡大学Björn Schuller团队长期致力于人工智能、音频识别、情感计算、机器学习的相关算法和研究领域, 其开发的OpenSMILE情感特征提取工具被广泛应用; 微软Microsoft研究院研究员利用CNN、RNN、LSTM等多种深度学习方法检测语音信号中的情感信息; 南加州大学Jonathan Gratch教授的研究方向主要包括虚拟机器人以及情感计算模型, 以及研究认知与情感的关系, SAIL(signal analysis and interpretation laboratory)实验室研究以人类交流为核心的信号及信息处理技术, 包括行为信号处理、情感计算、多模态信号处理、计算多媒体智能、计算语音科学等; 卡内基梅隆大学的人机交互研究(https://hcii.cmu.edu/research/audio-emotion-recognition)将提出的两阶段分层语音情感识别方法(two-stage hierarchical classification approach)应用于中风康复治疗虚拟教练中, 建议患者是否该休息、是否进行不同的锻炼; Virginia Affective Neuroscience Laboratory研究设计情感的神经科学机制研究、行为学研究、情感健康研究, 旨在为人类情感研究提供基础的理论研究, 利用EEG脑电图分析、fMRI成像技术研究人类大脑对情感的处理机制, 为推动情感识别、情感计算等的发展提供认知理论支撑及指导.瑞士情感中心(Swiss Center for Affective Sciences)是一个跨学科研究中心, 研究重点为情感或情感科学, 涉及认知神经科学、心理学、语言学、情感计算领域.除此之外, 日本北陆先端科学技术大学院大学、新加坡南洋理工大学、新加坡国立大学、新加坡资讯通信研究院、爱尔兰都柏林圣三一学院、英国格拉斯哥大学、德国帕绍大学、加拿大滑铁卢大学、美国得克萨斯州大学等国际众多院校或机构致力于情感智能相关领域的研究.
国内也有越来越多的科研单位加入该领域的研究, 如中科院自动化研究所主要研究听觉模式的分析和理解, 包括情感交互技术等; 清华大学多年从事语音信号处理方面的研究, 开发的“汉语文语转换系统Sonic”在文本分析、韵律模型、合成语音的自然度方面有重要突破; 东南大学从事语音信号处理、情感信息处理等研究, 在汉语连续语音韵律特征、F0的生成模型、声调处理、语音信号中的情感信息处理等方面取得了一些有价值的研究成果; 天津大学在语音识别、对话、言语认知脑机理、言语理解、情感计算等领域的研究成果也均处于领先地位; 哈尔滨工业大学在语音情感识别、情感大脑认知领域进行深入研究等; 浙江大学与阿里巴巴建立前沿技术联合研究中心, 在人工智能、情感计算及跨媒体分析等领域取得很好成果, 并联合发布“懂情感”人工智能系统Aliwood, 可以为视频所配音乐建立情感模型.除此之外, 北京邮电大学、电子科技大学、大连理工大学、华南理工大学、中国科学技术大学、山东大学、西北大学、南京邮电大学、太原理工大学等都在语音情感识别或多模态情感识别领域做出重要贡献.
近几年来, 随着研究者对人工智能领域的关注, 越来越多的会议与竞赛也进一步推动了情感识别研究的发展.语音识别领域顶会INTERSPEECH和ICASSP每年都有语音情感识别的议题, 2016年举办了第6届音/视频情感大赛(Audio/visual Emotion Challenge and Workshop, 简称AVEC 2016)[6], 2017年召开第1届国际情感计算与情感识别大会(1st Int’l Workshop on Affective Computing and Emotion Recognition, 简称ACER 2017), 会议议题涵盖了情感计算的方方面面.2018年, ACM多模态交互国际会议(ACM Int’l Conf. on Multimodal Interaction, 简称ICMI)中的Emotion Recognition in the Wild(EmotiW)竞赛[7]包括音视频情感识别子任务.国内也召开了该领域相关会议, 2016年, 全国模式识别学术会议的特殊议题即为第1届多模态情感识别竞赛(MEC 2016)[8], 该竞赛包括音频情感识别、表情识别和音视频融合的情感识别这3个子任务, 选用CHEAVD(CASIA Chinese emotional audio-visual database)作为数据库, 国内外共43个团队参加, 爱奇艺媒体智能组通过迁移学习的方法, 在8类音频情感识别任务中取得最高识别率44.22%.会议针对情感语料库建立、情感识别方法及应用展开深入讨论, 促进了整个领域的发展.2017年开展了第2届多模态情感识别竞赛(MEC2017)[9], 目标是提高真实环境下的情感识别性能, 数据库采用CHEAVD的扩展版2.0, 促进了汉语多模态情感识别的研究.2018年5月, 首届亚洲情感计算学术会议(ACII Asia 2018)在中国科学院自动化研究所召开, 围绕情感计算与智能交互进行探讨:情感认知、情感识别与生成、情感交互界面与系统、情感表达评价、情感对话系统、情感代理与机器人等, 是首个聚焦跨学科情感计算的亚洲论坛.
2018年, 中国科协发布了12个领域60个重大科学问题和工程技术难题, 其中, 信息科技领域的“人与机器的情感交互”位列其中, “无情感不智能”已成为众多研究者的共识.如何赋予机器人“情商”, 使其具有情感处理能力, 就成为服务机器人领域当前亟待突破的方向.目前, 美国、日本、德国、中国等纷纷开展了情感机器人的研究, 而识别情感则是实现情感交互的第一步.
语音情感识别的研究涉及诸多学科, 例如神经科学、心理学、认知科学、计算机科学等.情感理论是研究语音情感识别的基础, 人类情感极其复杂, 心理学领域已产生众多情感理论来解释人类情感[10, 11].目前, 基于语音的情感识别技术常用的情感理论模型有两种.
● 一种是离散情感模型, 定义几种“基本情感”, 其他情感由“基本情感”不同程度修改和组合[12].该模型虽然简洁但对情感的描述能力有限, 很难准确地描述自发情感.
● 另一种是维度情感模型把情感看作是逐渐的、平滑的转变, 不同的情感可以映射到高维空间上的一点[13].近年来, 该领域的研究也明显地呈现出由离散情感模型发展到维度情感模型的总体趋势[14-16].
本文将首先从情感的心理学研究基础展开, 介绍情感的评估理论与维度情感模型; 在语音情感的认知学研究进展方面, 将综述包括语音情感的大脑处理机制、情感计算模型以及脑启发的情感识别算法; 在语音信号分析方面, 将着重介绍语音维度情感识别技术, 包括语音音频信号预处理方法、特征提取方法以及情感预测算法、语音情感识别技术实现所需要用到的算法实现工具.最后分析了该领域存在的问题, 并提出今后研究的关键问题(如图 1所示).

|
Fig. 1 Survey framework of speech dimensional emotion recognition 图 1 语音维度情感识别研究综述框架 |
基本情感理论认为, 情感具有原型模式, 即存在数种基本情感类型.该理论将情感分为基本情感(basic/ primary/fundamental emotions)和次级情感(non-basic/secondary emotions).
● 基本情感固化在人类神经自主系统之中, 每类基本情感对应一个独特的、专门的神经通路, 能以特定的方式推动对他人和情境做出反应, 如语言声调、面部表情、身体姿态等.
● 次级情感是根据情感的调色板理论[17], 由基本情感混合而成.这些情感的表达方式具有跨文化差异, 其表达方式由社会化过程所决定.Izard把次级情感分为3类:第1类是由2~3种基本情感混合组成; 第2类是基本情感与内驱力的混合; 第3类为基本情绪与认知的组合.
基本情感的定义往往利用情感评估模型.情感是在比较个人需求与外部要求过程中诱发的, 反映个人与环境的关系, 可按照一套标准来描述或评估, 这套标准叫做评估变量(例如likelihood, desirability, unexpectedness, controllability, urgency, future expectancy)、检查项或评价维度.
1) Scherer成分处理模型
1984年, 日内瓦的瑞士情感科学研究中心的心理学教授Scherer提出情感成分处理模型(component process model)[18], 将情感定义为产生认知活动(cognitive component)、调控过程(peripheral efference component)、行为动机(motivational component)、行为表达(motor expression component)以及个人情感状态(subjective feeling component)的过程.情感表达是情感过程的成分表达, 通过评价结果进行模式化.Scherer[19]在后续研究中指出:当人类接触到事件后, 会产生简单、原始的动机趋力, 可通过含义评估(implication appraisal)检验事件的起因与可能带来的影响; 通过应对评估(coping appraisal)检验自己控制该事件的能力有多少, 或是当无法控制它时, 有多少调整的空间; 与通过标准显著度评价(normative significance appraisal)评估上述处理结果与自我道德规范标准或社会道德规范标准之间的一致性, 对该动机趋力进行评估与调整.
2) OCC情感模型
在评估理论中最有影响力的是1990年Ortony, Clore和Collins提出的OCC模型[20].OCC情感模型是早期对人类情感研究提出的最完整的离散认知情感论模型之一, 也是第一个以计算机实现为目的发展起来的模型. OCC模型定义了22类基本情感种类的形成规则以及3个层级(事件events、智能体agents、目标object), 通过以下5个步骤实现从最初事件的分类到产生个性行为的完整系统:1)对事件、行为或目标进行分类; 2)量化受到影响的情感的强度; 3)新产生情感与已存在情感的相互作用; 4)将情感状态映射到某种情感表达; 5)对情感状态进行表达.
3) Roseman评价理论
1996年, 美国罗格斯大学心理学教授Roseman[21]提出了具体的事件评价因素和执行计算的框架结构, 通过它们的相互作用来推断所合成的情感.评价因素分为意外、动机、情境、可能性、控制度、事件引发原因及问题类型, 其中, 动机与控制度是评估情感的最重要两个因素, 如:当情境与主体的目标不一致时, 常诱发消极情感, 例如生气或者后悔.他根据这7种评价因素给出17种基本情绪, 其中, 积极情感(动机一致)包括希望、高兴、安慰、喜欢、自豪; 消极情感包括生气、轻视、恐惧、悲伤、悲痛、厌恶、挫折、遗憾、内疚、羞愧; 某些情感, 如欲望、惊讶, 可根据事件引发原因决定积极情感或消极情感.Roseman所提出的基于事件评价的情感模型, 形成了一个较为完善的理论体系.
目前, 研究者们对基本情感尚未达成共识, 大部分观点认为存在6种基本情感:恐惧、高兴、愤怒、厌恶、悲伤和惊奇, Ortony和Turner将这些观点整理见表 1[12].
基本情感理论借助情感评估模型, 以不同的方式解释情感是如何产生以及演变的, 社会心理学研究者利用这种理论解释和预测人对事件的反应机制以及情绪模式.评估模型主要用于情感建模与合成, 如文献[22, 23]利用OCC模型合成情感, 且在机器人情感研究中广泛应用, 设计不同个性的情感机器人[24-26].评估模型基于离散情感描述模型, 可表达的情感类别有限, 且有些情感类别非常相似, 以至于环境很难触发这些情感[27].
1.2 维度情感模型(dimensional emotion model)任何情感发生时, 在某一属性或特性上可以有不同的幅值.情感维度就是对情感某种属性的度量, 维度具有极性.情感维度理论认为:情感状态不是独立存在的, 多个维度构成了人类情感空间, 不同情感之间是平滑过渡的, 利用维度空间中的距离可以表示不同情感的差异度与相似度.迄今为止, 研究者提出的维度划分方法多种多样, 并没有统一的标准评测哪种维度划分方法更好.典型的维度理论包括:
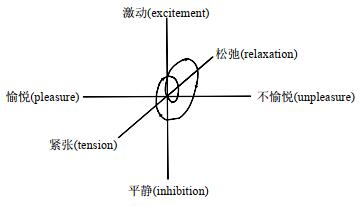
1. Wundt的情感三度说
Wundt在1863年提出情感的维度理论[28], 认为情感由愉悦(pleasure)-不愉悦(displeasure)、激动(excitement)-平静(inhibition)和紧张(tension)-松弛(relaxation)这3个维度组成, 每一种特定感情都是这3个维度以不同方式的独特组合.在一个特定的时间里, 作用于意识的感情总和被称之为总体感情(total feeling).它是同时存在的不同性质的器官感受的总和, 它们结合起来, 形成一个具有确定性质和强度的感情特征的组合体.从感情与观念的关系来看, 感情可以看作是伴随观念形成的一种过程, 某一时刻的情感在三维情感空间中表示为一个独立的点, 当对具体事件作出反应时, 情感可以表示成一条轨迹, 一般情况下, 轨迹的起始和重点都位于原点(如图 2所示).
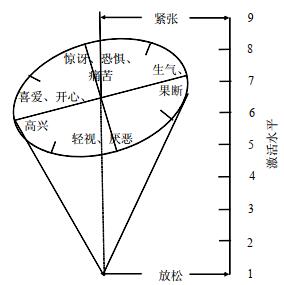
2. Schlosberg倒圆锥三维情感空间
Schlosberg[29]对Wundt理论中的激动-平静维度进行了进一步研究, 提出了激活度的概念, 并通过对面部表情的情感分类研究, 提出了由愉悦度、注意度、激活水平这3个维度构成的倒立圆锥形情感空间模型, 圆锥切面的长轴代表了情感的愉悦度变化, 短轴代表了情感的注意度变化, 垂直于椭圆面的轴表示激活度强度变化(如图 3所示).Schlosberg提出, 与愉悦情感相比, 不愉悦的情感具有更高的激活度.
3. PAD情感空间模型
Russell & Mehrabian[30]于1977年利用回归分析的方法研究愤怒(anger)和焦虑(anxiety)情感, 发现愤怒和焦虑都具有高激活度和低愉悦度, 但两者的优势度(dominance)明显不同:愤怒具有控制倾向, 焦虑具有服从倾向.结合先前的研究, 他们提出了PAD维度模型.该模型简洁且相对完善, 通过SAM(self assessment manikin)量表, 可以快速测定个体的情感状态, 因此被人工智能领域广泛认可.PAD模型由3个维度组成.
1) P代表情感的愉悦度维度(pleasure-displeasure):表征情绪状态的正负性, 已通过脑成像研究证实了愉悦度维度.
2) A代表情感的唤醒度/激活度维度(arousal-nonarousal):表示情绪生理激活水平和警觉性.
3) D代表情感的优势度维度(dominance-submissiveness):该维度反映在相对动机的比较中, 表示情绪对他人和外界环境的控制力和影响力.
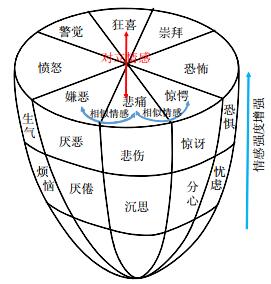
4. Plutchik抛物锥情感空间模型
Robert Plutchik于1984年提出8种基本的“两极”情感:高兴-悲伤、愤怒-恐惧、厌恶-信任、惊奇-期望[31].类似于三维颜色表达空间, 利用强度、相似性和两极性这3个维度来描述情绪模型, 基本情感可以表达为不同的强度, 基本情绪相互混合演化出次级情感.Plutchik采用倒锥体来描述情绪3个维度之间的关系.上述8种基本情绪组成了椎体的截面(如图 4所示), 相邻位置的情绪相似, 对角位置的情绪对立, 锥体自下而上表明情绪强度由弱到强.该模型的优点在于清晰地界定情绪, 并将情绪的相似性与对立性很形象地表达.Plutchik的情感结构理论与Schlosberg的情感模型相似, 都将激活度与颜色强度进行对比, 但Schlosberg提出的锥形情感空间未提出基本情感, 而是从理论上推导出3个维度.
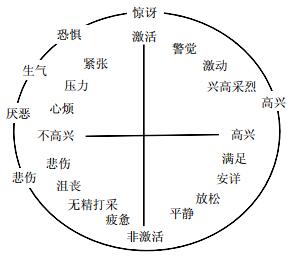
5. Russell的愉快度和强度环形模型[32]
Russell的后续研究表明, Schlosberg所提出的注意-拒绝和激活度是很难区分的.于是, 他于1980进一步研究了情感的环状模式, 提出了二维情感描述模型:愉悦度和强度(如图 5所示).
6.情感的高维空间模型
由于情感空间维度的数量没有定论, 所以部分学者根据自己的研究提出了高维空间模型.1974年, Krench[33]利用强度、紧张水平、复杂度和快乐度这四维模型来评定人体所处的情感状态; 1991年, Izard[34]提出的四维度分别是愉悦度、紧张度、激动度和确信度, 并编制了情感维度量表(DRS, DES)对情感体验的评定比较准确.Frijda也根据自己的研究提出六维情感模型, 分别是愉悦度、激活度、兴趣度、惊奇度、复杂度、社会评价.
1.3 离散情感描述模型与维度情感描述模型的关系尽管情感层次理论与维度空间理论分别利用不同的方法描述情感, 但是两者之间并不是对立的, 而是可以相互转换的.维度理论利用欧氏空间描述情感, 坐标轴的不同取值组合表示一种特定的情感状态, 但基本情感可以通过一定方式映射到情感空间中.Mehrabian[35]利用个性(personality)代表长期的情感, 采用开放性(openness)、尽责性(conscientiousness)、外向型(extraversion)、亲和性(agreeableness)和情绪稳定性(neuroticism)这5大特质来分析个性, 并研究了5个特质与PAD空间模型的内在关系, 提出了利用5个特质预测PAD值的方法.基于Mehrabian的理论, Gebhard[36]将OCC理论中的基本情感映射到三维PAD情感维度模型, 见表 2.Becker-Asano[37]根据情感的动态理论, 提出了将基本情感向PAD模型映射的方法.
李海峰、韩文静[38]在对语音情感识别综述中对比了离散情感描述模型与维度情感描述模型的优缺点:离散描述模型虽然较为简洁, 但只能刻画有限种类的情感类型, 其情感描述能力显示出较大局限性; 维度模型很好地化解了这一问题, 利用维度空间精确地量化情感, 减小情感标签的模糊性, 具有无限的情感描述能力, 更利于自发情感的描述, 近年来受到越来越多的关注.
2 语音情感的认知神经科学研究进展 2.1 情感的神经机制情感产生的脑机理研究经历了一个较长的过程, 受到神经解剖学、神经生理与认知心理学等相关科学发展的影响.思想家和科学家对情绪奥秘的探讨可以追溯到古代的臆测和神秘主义.直到文艺复兴以后, 如霍布斯(Hobbes)、洛克(Locke)、笛卡儿(Descartes)等带有唯物主义色彩的哲学家才把知觉、思维、知识、情绪等和神经与脑的活动联系了起来.1872年, 达尔文(Darwin)在《人和动物的表情》一书里论述了情绪的生物学基础, 强调了环境对情绪行为的作用, 形成了情绪生理心理学的雏形.其后的詹姆斯(James)提出了最早的情绪生理-心理学理论, 为探讨情绪的性质指出了一条必由之路.James-Lang理论(1885年)即情绪外周理论, 强调情绪的产生是植物神经系统活动的产物.1912年, Mills首次提出了情感的大脑右半球假说, 右脑更多地决定了人的空间感、抽象思维、音乐感与艺术性.1931年, Cannon提出了情绪的丘脑学说, 认为丘脑对情绪调节起着重要作用.随后, Papez提出了Papez环路理论, 认为下丘脑是情绪表达中心, 边缘系统是情绪体验部位.但当时, 这一回路并没得到科学研究证实.Maclean于1952年提出了情绪脑的概念, 划分了较为精细的情绪相关脑区网络, 得到研究者的广泛认同(如图 6所示).
20世纪60年代, 随着情绪生理-心理学的发展, 形成了诸多情绪理论学派:阿诺德(Arnold)的评价-兴奋论[40]认为:情绪的发生决定于对感觉刺激的评估, 而皮质兴奋是情绪行为的基础.普里布拉姆(Pribram)的“不协调”论[41]把大脑高级中枢实现的认识活动与情绪联系起来.20世纪中叶的信息革命导致了认知心理学的建立, 把人脑理解为一个信息加工系统, 形成了情绪的信息加工论.拉扎勒斯(Lazarus)的认知-评价理论[42]从心理学的角度填充了信息加工过程的心理内容, 着重于外界刺激与行为反应之间的认知评价环节, 丰富了脑内信息加工的内容.LeDoux[43]根据神经生理学上的研究提出, 边缘系统对听觉刺激引起的情感响应起着至关重要的作用.边缘系统负责处理情感刺激, 主要包括4部分:感觉皮层、丘脑、眼眶额叶皮层、杏仁体[44, 45].随着脑成像技术的发展, 研究者对情感的大脑活动的研究也越来越精确.2004年, Florin利用fMRI对不同唤醒度、效价度情感刺激下的前额叶皮层活动进行研究, 实验结果说明:前额叶皮层(PFC)左侧对效价度积极的情感反应更活跃, 背外侧PFC对唤醒度更加敏感.2005年, LeDoux与Phelps[46]研究了动物模型及人类行为中杏仁体对情感处理的作用. 2008年, Mathersul[47]研究了脑电信号EEG的alpha波段与悲伤生气情感的关系.2014年, 康奈尔大学神经学家Adam Anderson[48]研究眼窝前额皮层的精细神经活动模式, 发现虽然情感是个人的和主观的, 但是人的大脑会把它们转换成一个标准的代码, 这个代码客观地代表着不同感官、情况甚至人的情感.2018年, Kirkby等人[49]利用半慢性颅内脑电图(iEEG)记录边缘系统的多位点, 并周期性地评估被试的情绪, 研究情绪和焦虑的神经编码, 并揭示一个生物指标, 有助于诊断和治疗情绪和焦虑障碍(如图 7所示).

|
Fig. 7 Timeline of historical milestones in researches of the emotional brain 图 7 情感大脑研究的重要里程碑工作 |
近年来, 功能性磁共振成像fMRI(functional magnetic resonance imaging)技术与脑电图EEG(electroenc ephalo graphy)技术为人类情绪的中枢神经机制研究提供了大量的研究证据, 初步揭示了人类情绪管理过程中大脑的区域功能和神经机制(如图 8所示).

|
Fig. 8 Diagram of human emotion management system 图 8 人类情绪管理系统示意图 |
(1) 情绪感知:枕叶加工视觉信息, 顶叶进行躯体感觉整合和空间视觉整合, 颞叶进行听觉性言语功能处理, 岛叶接受来自内脏和躯体状态改变的感知信号.
(2) 认知评价:眶额皮层、腹内侧前额皮层对情绪信息进行高级再加工, 完成对情绪刺激动机意义的评价.
(3) 主观调整:前部扣带回负责情绪加工中的冲突监控; 杏仁核通过与海马系统的相互作用, 可以使情绪性事件的陈述性记忆变得更加巩固.
(4) 自主活动:颞上回与社会性情绪相关, 完成对精细感觉的加工; 后扣带皮层与评断道德价值有关.
(5) 外显行为:脑干和下丘脑调节情绪活动中的躯体与自主反应, 实现人类的情感行为表达.
在情绪神经机制研究方面, Lindquist[50]对比了两种情感加工脑机制的研究方法.
● 一种方法是Locationist方法.该方法假设离散的情感类别是由其对应的不同脑区产生, 例如恐惧对应于杏仁核(amygdala)的激活、厌恶对应于脑岛区(insula)的激活、生气对应于眶额叶皮层(orbitofrontal cortex, 简称OFC)的激活、悲伤对应于前扣带皮层(anterior cingulate cortex, 简称ACC)的激活.
● 另一种方法是心理学建构论方法(psychological constructionist approach).该方法假设情感状态是由大脑功能网络的相互作用形成, 杏仁核、脑岛、腹内侧眶额皮层、前扣带皮层、丘脑都参与多个主要情感的形成.
Lindquist等人通过对大量人类情感的神经影像学文献的总结, 认为更多地证据与构建论一致, 不同的大脑区域相互作用共同参与情感的体验与感知.
更具体地, 大脑如何处理语音情感, 也是听觉语言处理研究的一个热门课题.语义信息以及韵律线索对语音情感的理解起着重要作用.有研究表明:大脑右半球负责处理情感韵律信息[51-54], 但实验的任务类型或者被试默读复述也可能引起双边激活模式.Ross[55, 56]的偏侧性假设认为:无论情感激活度如何, 大脑右半球在处理情感语音时更具有优越性.与之相比, 激活度假设[57]认为:大脑左半球对积极情感具有主导性控制, 右半球主要控制消极情感.由于韵律信息随着声学参数变化, 如基频f0、强度以及时长等, Zatorre[58]提出了右半脑负责基频信息的感知, 左半脑处理强度以及时长信息.文献[59-62]利用fMRI技术研究语音情感表达时脑区的激活程度.Kotz[63]研究发现, 具体的语音情感表达由大脑的额叶-岛盖-颞叶(fronto-operculo-temporal)区进行编码, 颞叶区负责副语言声学处理, 额叶区进行情感评估, 左侧颞叶-小脑(temporo-cerebellar)区负责时序处理, 右侧额下回(inferior frontal)区分不同的情感表达.文献[64]研究发现, 通过情境上下文的学习, 通过语义与非语言获得情感意图的途径一致.语境学习假设认为:情感状态基于个人对该情感以往的学习经验, 情感系统由预先定义的概念进行评估, 然后根据经验进行精细处理.
2.2 情感计算模型情感相关的认知神经科学的研究, 促进了情感计算模型的发展, 产生了一系列能实现情感计算的系统.目前, 较多的情感计算模型是基于情感认知理论.Elliott实现了一个基于OCC模型的情感推理机(affective reasoner)系统[65], 每一种情绪都由一组不同的认知导出条件通过推理得出.Reilly实现了一个可以及时更新情绪状态的EM系统[66].Gratch等人将认知过程引入情感的研究, 提出了一种能够解释情感动态变化过程的EMA[67]系统.MIT人工智能实验室的Velasquez提出了一种新的情感更新规则, 由此开发了一个能够控制各类情感现象的动态变化的Cathexis模型[68].
ALMA多层次情感模型[36]利用OCC Model测量短期情感、PAD情感量表中期情感(mood)以及五大人格特质来衡量长期情感状态, 该模型对情感进行了更完整的定义, 可以更自然地实现不同情感的语言或非语言的情感表达.
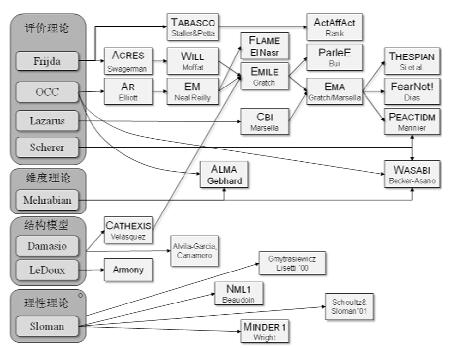
Becker-Asano提出了WASABI[37]情感计算模型, 该模型融合了基于维度情感理论的情感动态更新规则以及OCC情感评估理论.与其他基于OCC理论的计算模型相比, 该模型建立了更加完整的反馈机制.Marsella[69]将情感计算模型总结如图 9所示.
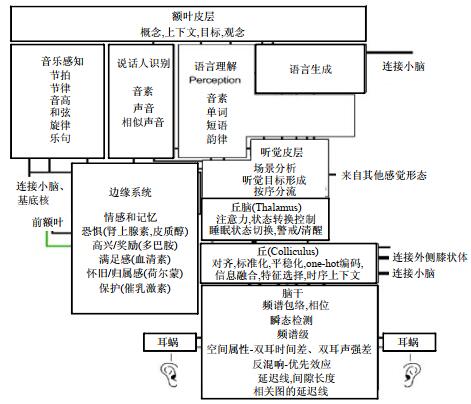
听觉通路从听觉信息的感知、说话人识别、语音感知到言语生成分为不同的等级[70], 语音进入左右耳蜗, 耳蜗相当于一个滤波器组, 将声音以时频谱的形式呈现, 并以相应的神经电信号方式传递至低位脑干, 低位脑干负责预处理、缩放和归一化, 之后信号进入下丘脑、上丘脑和丘脑区, 丘脑负责控制注意力, 并产生信号传递至边缘系统和主要的听觉皮层.最后, 经边缘系统和听觉皮层处理的信号再经过特定的通路进行语音识别、言语生成、说话人识别和音乐感知等(如图 10所示)[70].
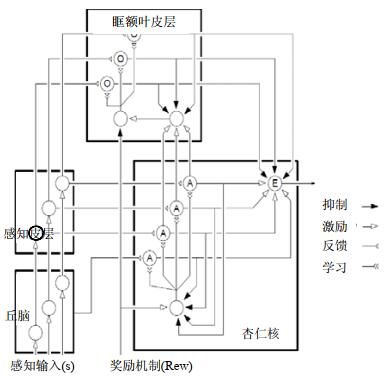
根据大脑边缘系统的结构, Morén等人提出了大脑情感学习模型(brain emotional learning model, 简称BEL model)[45], 对边缘系统4个部分之间的情感学习机制进行数学建模, 采用一种基于奖励信号的强化学习方法调节模型参数, 并通过实验证明BEL模型的输出对奖励信号有明显依赖性(如图 11所示).该模型在混沌时序预测领域取得广泛应用[71-73], 与神经网络模型相比, 具有结构简单、计算复杂度低等优点; 但是关于奖励信号的设定方法目前没有统一的规定.随后, 出现了一系列优化BEL模型参数的研究, 如:Lotfi等人[74]设计了竞争型BEL模型并采用遗传算法优化其参数, 增强了其处理高维多分类数据的能力; Lucas等人[75]在BEL模型的基础上, 利用感知输入与情感线索的行为产生机制, 提出了BELBIC智能控制器, 并将该控制器用于非线性系统中, 验证了其具有很好的控制能力、抗干扰能力和系统鲁棒性.Parsapoor[76]利用模糊推理系统(fuzzy inference system)对BEL模型的杏仁体和眶额叶皮层模块进行优化, 得到BELFIS模型.Motamed等人[77]利用自适应神经模糊推理系统(adaptive neuro-fuzzy inference system, 简称ANFIS)和多层感知器(multilayer perception, 简称MLP)对BEL模型进行改进, 用于语音情感识别, 并在Berlin语音情感数据库上进行实验, 与SVM、KNN、BEL、BELFIS、BELBLA模型的实验结果进行了对比, 提出的算法取得更高的识别率(如图 12所示).

|
Fig. 12 An optimized model of BELthat merges the ANFIS and MLP for speech emotion recognition[77] 图 12 基于ANFIS和MLP改进的BEL模型用于语音情感识别[77] |
借鉴人类情绪机制的类脑情感计算研究已经开始, 在人脑这个“巨象”上, 研究工作者面临着如何深入解读大脑功能和揭示这个开放的复杂巨系统运行机制的挑战.
3 语音维度情感识别技术研究进展语音情感识别系统是经典的模式识别系统, 包括系统训练阶段和测试阶段.对于采集的语音信号均先进行预处理后, 根据情感空间描述模型的不同, 进行特征分析与识别任务技术设计(如图 13所示).对于离散情感描述模型, 语音情感识别任务可视为多分类问题, 为样本预测离散型类别标签; 对于维度情感模型, 其任务可视为回归预测问题, 为样本预测连续输出量的问题.分类问题与回归问题采用的建模方法以及性能评价指标不同:分类模型经常为输入样本预测得到与每一类别对应的像概率一样的连续值, 这些概率可以被解释为样本属于每个类别的似然度或者置信度, 预测到的概率可以通过选择概率最高的来转换成类别标签; 回归预测问题预测的是情感在不同维度上的连续数值, 其性能可以用预测结果中的错误来评价.在特定条件下, 分类问题和回归问题是可以相互转换的.如:Grimm等人在离散情感识别任务中, 首先将提取的全局统计特征利用模糊逻辑系统(fuzzy logic system)映射到连续三维情感空间, 再利用KNN识别为离散的7类情感[78].虽然DNN技术的广泛使用使得大量工作不需要进行数据预处理, 但语音信号有着低信噪比的特殊性, 众多学者对语音信号的预处理方法进行了大量研究.因此在本文中, 将就预处理技术、特征提取技术及分类器设计等方面进行综述.

|
Fig. 13 Framework of a speech emotion recognition system 图 13 语音情感识别系统框架 |
特征提取与处理, 是语音情感识别中重要的部分, 特征集直接影响识别器的识别能力和鲁棒性.特征提取的目的是从语音信号中提取一方面能表征不同识别单元的声学差异, 另一方面有能表征相同识别单元不同样本之间的声学相似性的信息.
语音情感信息通过语义和非语义两种形式传递:语义信息以一定的语言规则(语法、修辞等)传递说话者的情感; 非语义语音情感信息包括两种形式——情绪韵律(emotional prosody)[79]和非语言发声(non-linguistic vocalizations)[80, 81].
3.1.1 声学特征人们可通过感知语音中的声学线索, 从中提取出所携载的情感倾向.声学特征是独立于语言内容而传递的情感信息, 不受文化差异的影响, 对于不同语种的情感数据库, 均可通过提取声学特征进行情感识别[82-86].声学特征可分为LLDs特征(low-level descriptors)和统计特征(functions), 其中, LLDs特征常常以帧为单位进行提取, 可以从韵律特征、谱特征、音质特征对语音情感信息进行表达; 统计特征一般是将LLD特征在独立的语句或单词上进行统计, 包括极值、方差、峰度、偏斜度等.
1. LLDs特征
(1) 韵律特征
韵律特征被认为是与发音单元(音节、单词、短语、句子)相关联的声学特征, 又被称为“超音段特征”, 在情感识别中应用非常广泛[87-89], 主要包括时间特性、基频、能量等, 被认为与情感的感知具有明显的关系.文献[90]得出韵律特征与唤醒度相关, 音质特征与愉悦度相关的结论.Pereira等人[91]分析了语音韵律特征与情感维度的相关性, 数据结果表明, 基音等韵律参数与维度空间中的唤醒度对应.一般认为, 音质参数与维度空间中的效价度对应[92].
近来, 研究者提出了一些新的韵律特征.Arias[93]利用函数型数据分析(FDA)建立中性参照模型, 计算基音频率的主成分分析(PCA)映射矩阵作为每条语音的特征.具有高激活度的语音情感信号, 其能量多集中在高频成分, 低激活度的情感语音信号的基频较低[94].Sant’Ana[95]提出了赫斯特指数(Hurst exponent)用于说话人识别, Zao[96]进一步提出pH时频声源特征与情感的愉悦度相关, 取得了较MFCC, TEO-CB-Auto-Env特征集更高的识别率.Mencattini[97]提出了基于CQT的频域幅值包络特征, 并结合能量、小波近似分量和细节分量、过零率、共振峰、TEO等特征, 共520维特征用于维度情感识别.
(2) 音质特征
音质特征描述声门属性, 语音的音质特征主要指具有不同情感状态的说话人发音方式上的区别.Scherer的情感成分处理模型提到音质特征影响情感的变化.Tato等人[98]探讨了情感维度对语音识别的贡献, 研究发现, 音质类特征对于区分唤醒维接近而效价维远离的情感(生气和喜悦)有较好的效果.
Borchert[92]将共振峰、不同频带的频谱能力分布、谐波噪声比、频率微扰和振幅微扰在内的音质特征用于效价度预测, 将韵律学特征用于激活度预测.实验结果表明, 音质特征更适用于区分唤醒度相同、效价度不同的情感.Idris[99]利用音质特征集、韵律学特征集以及二者混合特征集, 选用多层感知器网络分别在柏林情感数据库上进行情感识别, 平均识别率分别是59.63%, 64.67%和75.51%.Kachele[100]将谱特征、韵律学特征和音质特征用于表达语音的长时信息, 并利用改进的前向选择/后向剔除算法进行特征选择, 在公开的柏林情感数据库上进行测试, 平均识别率为88.97%.
(3) 谱特征
谱特征通常用来表示发声器官的物理特征, 是信号的短时表示, 一般认为在很短时间内(10~30ms)相对平稳, 可以通过某时刻附近一段短语音信号得到一个频谱.频谱表示频率与能量的关系, 有助于更好地观察音素.常见的频谱图主要有线性振幅谱、对数振幅谱、自功率谱.谱特征主要有线性预测系数(linear predictor coefficients, 简称LPC)、线谱对参数(line spectrum pair, 简称LSP)、单边自相关线性预测系数(one-sided autocorrelation linear predictor coefficients, 简称OSALPC)等.频谱图中的共振峰携带了声音的辨识属性, 利用倒谱可以提取包络信息, 得到共振峰用于识别.常见的倒谱特征有感知线性预测倒谱系数(perceptual linear predictive cepstral coefficients, 简称PLP)、线性预测倒谱系数(linear predictor cepstral coefficients, 简称LPCC)、单边自相关线性预测倒谱系数(one-side autocorrelation linear predictor cepstral coefficients, 简称OSALPCC).考虑到人耳听觉系统响应不同频率信号的灵敏度不同, 将线性频谱映射到基于听觉感知的Mel非线性频谱中, 再进行倒谱转换, 得到Mel倒谱系数(Mel frequency cepstrum coefficients, 简称MFCC).MFCC已广泛应用于语音识别、情感识别领域.
另外, 最近研究者们也提出了一些新的谱特征.Huang[101]提出一种基于小波包的自适应滤波器组构建方法(wavelet packet cepstral coefficients, 简称WPCC), 对MFCC有很好的扩展作用, 而且可以利用2D的小波包进行图像处理, 适用于语音视觉多模态情感识别系统.Ziolko[102]提出了Fourier-Wavelet特征提取方法, 首先对语音信号进行小波变换, 然后再进行傅里叶变换.Idris[103]提出两种谱特征优化方法:一种方法是基于离散谱特征的优化, 一种是融合谱特征.利用这两种优化方法得到的特征集合进行情感识别, 识别率较优化前分别提高2%和4%.Espinosa等人[104]在VAM数据集上测试了韵律学特征集合、音质特征集、谱特征集对PAD维度空间识别率的影响.Wang等人[105]提出了新颖的傅里叶参数模型组合傅里叶参数及其一阶、二阶差分用于语音情感识别, 并利用提出的特征与MFCC结合提供了说话人独立的语音情感识别.Ghosh等人[106]从语音信号及声门流量信号中提取频谱图, 利用堆叠的自编码方法进行频谱图编码, 最后利用RNN进行4类情感识别, 采用基于声门流量信号的表征学习模型与基于效价度和唤醒度分类训练的迁移模型来提高RNN训练效率.实验结果显示:表征模型与迁移模型的加入, 可以提高1.17%的识别率.
2.统计特征
进行语音情感识别时, 帧特征往往不直接作为网络输入进行学习, 而是利用这些特征的一些统计值进行神经网络训练.表 3给出了常用的统计特征.
| Table 3 LLDs and functions 表 3 LLDs特征以及统计特征 |
Schuller等人[107]在一个AVIC(audiovisual interest corpus)语料库上分别利用帧特征和全局统计特征进行语音对话兴趣识别, 他们首先提取了包括基频、能量、MFCC、共振峰、频率微扰、振幅微扰、谐噪比等37维LLD特征曲线, 然后统计出每条曲线的最大值、最小值、均值、方差、峰度、偏斜度等共19维全局特征统计值, 最后, 分别利用MI-SVM(multi-instance learning-SVM)和SVM对LLD特征和统计特征进行兴趣识别, 定量对比其识别准确率.实验结果表明, 基于统计特征的识别结果比帧特征的识别结果更加准确.
情境上下文对情感的识别具有关键性作用, 长时统计特征在区分高激活度和低激活度情感语音的效果较好, 但是对激活度相同情感的区分能力较弱, 如很难区分具有相同激活度的生气和欢乐情感语音.具有时序信息的帧特征在区别效价度不同的情感语音[108].
目前, 已有少量文献尝试选取不同窗长来提高情感识别率, 但存在的文献没有统一的答案.Origlia[109]认为:目前, 特征提取方法是基于整个语音信号, 没有考虑语音内容的变化, 这与韵律研究的理论基础是矛盾的.并以此提出一种基于音节的特征提取办法, 同时考虑音节核, 可以减少信息的处理量.Sethu[110]认为, 帧特征和全局统计特征不足以全面的表征情感的时序信息.因此提出以段为单位的特征提取, 可通过基音频率和前3个共振峰的轮廓进行提取, 将该特征与短时帧特征和全局统计特征融合可以提高情感识别率.李海峰等人[111]使用“语段特征”用于识别, 并给出了各类情感状态对应的“最佳识别段长”, 构建了全局控制Elman神经网络用于将全局统计特征与基于语段的时序特征相融合.随后, 该团队又提出了一种基于不同时间单元的多粒度特征提取方法, 以及可以融合多粒度特征的基于认知机理的回馈神经网络(cognition-inspired recurrent neural network, 简称CIRNN)[112].该网络既突出了情感的时序性, 也保留了全局特性对情感识别的作用, 实现多层级信息融合.Deng等人[113]利用Bag-of-Audio-Words(BoAW)算法代替传统的统计特征, 该方法针对LLDs特征, 利用k均值聚类方法或随机采样方法生成编码本(codebook), 再利用多重赋值量化技术(multi-assignment quantisation)将每帧语音信号提取的LLDs特征分配到相应的编码本得到直方图, 将直方图归一化后作为特征用于识别.
3.1.2 语音信号中的语义信息语音信号中传递的语义信息对于情感识别具有一定的作用, 有些特定的词汇可以表达相应的情感倾向. Lee等人[114]将声学特征、句法、语篇信息相结合用于情感识别, 引入情感显著性的信息理论来表达语言层面的情感信息.对电话服务中心数据的实验结果表明, 融合特征可以有效地提高情感识别率.Schuller[115]提出一种新的方法将声学特征与语义信息融合用于情感识别:首先, 提取声学特征利用分类器进行识别; 然后, 利用置信网络根据语义上下文进行识别; 最后, 利用Neural Net将两次识别结果进行决策融合.Wu等人[116](2011)将语义标签识别结果与声学韵律信息融合来提高语音情感识别结果, 语义标签来自知网汉语知识库(Chinese knowledge base HowNet), 用于自动提取情感关联规则(emotion association rules, 简称EARs).
3.2 语音维度情感预测器情感识别通过获取人类情感信息, 识别人类的情感, 提高机器与人之间自然交互能力.根据情感描述模型的不同, 语音情感识别系统采用的识别算法亦不同.维度语音情感识别问题可建模为回归预测问题, 常见的回归预测算法包括线性回归(linear regression)、k-NN、ANN、PLS、SVR, 当前新兴的深度神经网络如LSTM、RNN等.
偏最小二乘法(PLS)[117, 118]结合了主成分分析PCA和典型相关分析CCA的思想, 适用于特征集较大并且存在多重共线性的预测建模问题.Mencattini[97]将7类离散情感投影到二维情感空间描述模型(效价度-激活度)中, 采用偏最小二乘法回归(PLSR)模型在印度语音数据库EMOVO上对男性、女性发音语料进行情感预测, 平均判决系数分别为0.89和0.72.
SVR是支持向量在函数回归领域的应用[119-121], Grimm等人[122]在VAM数据库上利用SVR在效价度、激活度和控制度这3维情感属性上进行情感预测, 其性能优于k-NN、基于规则的逻辑分类器(rule-based fuzzy logic classifier).Giannakopoulos等人[123]利用效价度-唤醒度的二维情感空间描述情感状态, 并使用k近邻算法(k-NN)对电影剪辑语句的情感坐标值进行估计.Kanluan等人[124]在VAM数据库上进行多模态情感识别, 提取韵律学特征、谱特征等声学特征以及基于二维离散余弦变换的面部图片特征, 利用SVR分别进行语音情感识别和面部情感识别, 再利用决策级融合方法将两种模态预测结果进行权重线性融合, 预测结果较语音情感识别提高12.3%.
LSTM网络使用特殊的神经元在长时间范围内存储并传递信息, 适合于处理和预测时间序列中长时间延迟的信号, 因此, 该网络可以记忆情感随时间的变化信息.利用长短时记忆循环网络(LSTM-RNN)进行维度情感识别, 取得了比传统方法更好的效果.Wöllmer[125]采用AVEC 2011(Audio/Visual Emotion Challenge 2011)[126]情感竞赛提供的声学特征结合面部运动特征, 在SEMAINE情感数据库上进行音视频情感维度识别.实验结果表明:与其他参赛者提供的情感识别模型相比, 基于LSTM网络的平均识别效果最好.Ringeval等人[15]将LSTM- RNN用于音频、视频、生理信号的多模态维度情感识别, 该网络可以动态地利用长时间的上下文信息, 同时避免RNN网络的梯度消失问题.文中比较了不同窗长对各模态情感识别结果的影响, 以及特征级融合与决策级融合方法的识别效果.研究结果表明:效价度的情感识别比激活度需要更长的窗长, 决策级融合取得更好的识别效果.在RECOLA数据库上, 该模型在激活度和效价度上的一致相关系数分别可达到0.804和0.528.Chao等人[127]利用时间池对输入特征进行时间建模, 并引入ε不敏感损失函数改进LSTM-RNN模型, 使其对标注噪声具有更好的鲁棒性.该模型在RECOLA数据库上对效价度和唤醒度进行情感识别都取得了更好的效果, 但在唤醒度上存在过拟合现象.
国内也有越来越多的学者提出新颖的语音维度情感识别方法.陈逸灵等人[128]利用MFCC特征, 结合语谱图中提取时间点火序列特征、点火位置信息特征这3种特征分别用于语音情感识别, 并将识别结果与PAD (pleasure, arousal, dominance)维度进行相关性分析, 得到特征的权重系数, 加权融合后获得情感语音的最终PAD值.李海峰等人[129]通过构建对情感程度相对顺序敏感的Dim-SER系统, 提出了顺序敏感的神经网络算法.实验结果表明, 该网络性能较常用的k近邻算法和支持向量回归算法相比有了提升.
目前, 上述基于单一数据的语音情感识别性能已经取得了很大的提升.然而, 在很多实际应用情境下, 系统必须考虑文化、语言、种族、个体、年龄等影响下数据的情感分类.从大脑工作神经机制来讲, 不同种族、文化等人群对情感的反应具有一致生理生化基础, 康奈尔大学神经学家Anderson的一项研究表明, 人的大脑会使用一种标准的代码来说出同样的情感语言[48].人的大脑会对从愉悦到不愉悦、好到坏的感觉产生一种特殊的代码, 读起来就像一个“神经价表”.在这个价表中, 一组神经元在一个方向倾斜等同于积极情绪, 其他方向的倾斜则等同于消极情绪.虽然存在一致性的生理基础, 但是文化对于个体的态度、行为、语言或非语言的反应都有着潜移默化的影响, 这些差异影响了人类跨文化情感表达、感知与理解.有情感心理学研究表明, 文化背景对于个体如何利用面部和声音线索从多感官刺激中有意识地评估情感含义有着重要的影响[130-132].Elfenbein和Ambady[133]发现, 同种族或者区域的人群具有比较一致的情感表达和识别方式, 情感识别会更加精准一些.上述心理学及认知学研究表明:从大脑脑区的精细神经活动模式角度看, 情感感知存在着相似性, 但是文化背景、语言、个体差异又影响着情感的感知.在共同的信息加工机制下, 进行跨文化、跨种族等语音情感识别有了理论基础.Peng[134]提出一种迁移线性子空间学习(transfor linear subspace learning, 简称TLSL)网络框架进行跨库语音情感识别, 在学习的投影子空间中提取鲁棒的跨库特征表征, 其优势是解决了当前大多数迁移学习只专注于寻找最可能迁移的特征的缺陷.通过结合实验, 证明TLSL用于跨库语音情感识别是有效的.Hesam等人[135]利用基于自动语言检测的模型, 可以提高多语言情感识别的准确率.在3种语言(德语、罗曼语系、汉藏语)的6个数据库上进行测评, 将情感分别在效价度与唤醒度上进行分类.实验结果说明:尽管语音情感识别更多地依赖于声学特征, 但其语言学信息可以提供话者文化背景相关的有用信息.通过识别话者的语言作为先验知识, 基于该知识的学习模型可以提高情感识别系统的性能.Kaya等人[136]采用融合了线性说话人归一化、能量归一化、特征向量归一化的级联归一化方法, 以减少跨库以及不同说话人差异带来的影响, 并利用极限学习机(extreme learning machines, 简称ELM)在跨语系的5种语言情感数据库上测试该归一化方法的有效性.Silvia与Schuller[137]于2015年情感计算国际会议ACII上, 对跨语言声学情感识别做了综述及前景展望.
4 维度语音情感识别研究的相关资源 4.1 语音维度情感数据库情感数据库是语音情感识别的先决条件, 提供训练与测试用语音样本, 数据库的质量直接影响情感识别率以及研究结果的可靠性.目前, 语音情感识别领域以离散情感数据库居多, 如Belfast情感数据库、EMO-DB德语情感数据库、FAU AIBO儿童德语情感数据库、CASIA汉语情感语料库、ACCorpus汉语情感数据库等, 维度情感语料库有待进一步丰富.下文首先介绍维度语音数据库的建立与标注方法, 然后介绍一些代表性的维度情感数据库.
4.1.1 情感数据库的建立根据语料的情感自然度程度的不同, 情感语音数据库的建立方法主要有3种.
(1) 自然情感语料:从现实生活中采集真实的自然语料, 进一步通过人工筛选与标注的方法获得可用语料.这类情感语料具有最高的自然度, 可以认为是真实意义上的情感语料.这种语料在使用前必须进行分类标注, 由于分类的标准不统一, 并且有些情感人类自身也难以区分, 因此这类情感语料具有一定局限性.
(2) 模拟情感语料:由专业或善于表达情感的人进行情感模仿录制语料.这种有目的性录制的特定情感语料具有更好的区分性, 但这种语料的情感自然度取决于录音者的模仿能力, 有时情感成分被夸大而不能体现真实的情感.
(3) 诱导情感语料:利用情景短片或者角色扮演的方式营造相应的环境氛围, 从而诱导录音者产生特定情感后录音.利用该方法获得的语料接近真实情感, 但由于环境诱发刺激效果很难评测, 导致较难判断诱发的情感是否强烈.
4.1.2 情感数据库的标注语音情感数据库的标注是一个困难但又极为重要的工作, 数据标注的质量对基于语音的情感研究有着重要的意义.实现较为精确的语音情感标注通常需要3个方面:音字转写(transcription)、注解(annotation)、标注(labelling)[138].音字转写是将音频中的语言信息以文字的形式转写标注, 即将语音转化为文字; 注解是在转写基础上进一步的标注韵律信息、语速、音量/调变化等副语言特征; 标注是对语句进行情感状态的标记.目前, 转写与注解已经有一些较为成熟的工具和软件, 如Anvil, EX-MARaLDA, Partitur Editor, Praat等, 这些软件各有优势.情感标注(labelling)工具可以方便地实现对语音情感的连续性变化的跟踪(此节以维度情感的标注方法为主). Cowie等人[139]开发了实时的效价度-唤醒度二维情感标注工具Feeltrace, 可用于动态情绪的标注与分析, 标注者根据自己感知的情感, 实时地利用鼠标拖动圆形光标到合适位置即可实现标注.Emocards量表根据Russell的情感环状理论, 用环状布局的16张卡通表情图片描述情感, 在愉悦度和紧张度两个维度上测量情感[140].Bradley等人[141]依据PAD情感空间模型提出SAM量表, 以图形化的方式从愉悦度、唤醒度和优势度由弱到强进行9级评分, 每个维度由逐渐变化的小人图片代表.SAM量表已经被证实可以有效地评定被试的情感感觉[142]. Broekens[143]开发了在线情感测量工具AffectButton, 仅包含一个按钮, 按钮表面是一张动态变化的卡通脸部图片, 鼠标的(x, y)坐标映射到PAD三维空间模型中, 表情图片随鼠标的移动而改变.AffectButton比SAM更加形象、简便, 一个按键可以反馈三维信息.ANNEMO[144]是基于网页的音视频维度情感标注工具, 可同时显示音视频与标注界面, 可进行时间连续的标记.Ikannotate[145]工具将上述三方面融合, 可以实现转写、注解、标注以及标注的不确定.
标注时须有一定的规则, 包括标注的一致性、连贯性、标注符号的易记性, 但同时还需要遵循的一条原则是允许标注的不确定性和差异性存在, 即允许不同的标注者对同一条语音中的情感、重音、声调等有不同的理解, 避免向用户提供错误信息.
4.1.3 具有代表性的维度情感数据库近些年来, 随着研究者们对维度情感识别领域的关注, 一些公开的以科学研究为目的的维度情感数据库逐渐被发布.尽管完整的语音情感数据库应包括转写、注解、情感标注, 但目前, 维度语音情感数据库的标注往往只包含对整句或段的情感标注.因此, 构建公认的有效、全面、优质的语音情感数据库, 是语音情感计算研究的重中之重.
VAM数据库(vera am mittag database)现场录制了12个小时的德语电视谈话节目[146], 谈话内容均为无脚本限制、无情绪引导的纯自然交流, 该库是一个包含视频库、语音库、表情库的多模态情感数据库.视频库(VAM- Video)包括104个说话人的1 421个视频, 语音库与表情库是从该视频库中分离获得.
● 语音库又分为两部分:一部分为非常明显的情感表达, 包括19个不同说话人的499个语句, 由17个听者在Valence、Activation、Dominance这3个维度利用SAM进行标注, 可用于维度语音情感识别研究; 另一部分包括28位说话人的519个语句, 由6位听者进行标注.
● 表情库包括20位说话者的1 867幅表情图片, 涵盖高兴、生气、悲伤、厌恶、恐惧、惊讶的6类情感以及中性情感, 可用于表情识别研究.
Semaine数据库是一个音视频情感数据库[147], 数据录制了用户与性格迥异的4个机器角色的交谈对话, 在3种情景下录制:一种是Solid SAL(sensitive artificial listener), 该情境下, 操作者扮演了SAL的角色, 录制了用户与角色的95段交互、190个视频片段; 第2种是半自动SAL(semi-automatic SAL), 该情景需要操作者选择一系列日常用语, 该语句已提前被表演者以与某种性格匹配的声音录制, 再以图形界面交互的方式展现给用户, 总共录制了1 410分钟用户与机器角色的视频数据; 第3种是自动SAL(automatic SAL), 该情境下, 角色表达的语句及非言语表达完全由SEMAINE系统自动的生成.该系统同时检测用户的情感变化并由摄像头记录下来, 用户与角色交互视频共计1 266分钟.对话由多个参与者借助标注工具Feeltrace在Activation、Valence、Power、Anticipation/Expectation和Intensity这5个情感维度上进行标注.该数据库中的部分数据被用作AVEC2012的竞赛数据库[148].
Recola数据库是一个多模态法语情感数据库[144], 包括音频、视频、生理数据(ECG和EDA).该数据库录制了9.5小时的视频会议, 连续同步记录了46名参与者的自然交流.6名法语助理通过ANNEMO标注工具, 在Arousal, Valence维度上进行标注.最终, 34名参与者同意共享数据, 数据时长共计7小时, 其中包括27名参与者5.5小时的生理数据.
USC IEMOCAP(interactive emotional dyadic motion capture)数据库[149]是一个英语情感数据库, 包括10个说话人参与的相互交流的音视频.将总计12小时的音视频数据分割成10 039段语句, 既包括有情感脚本的情感表演, 也包括即兴情感表达场景.每个语句由3名标注者进行离散情感标注, 包括高兴、生气、悲伤、中性、挫败感这5类情感, 标注者也可根据理解标注为其他情感类别.2名标注者在Arousal、Valence、Dominance这3个维度进行维度空间标注, 每个维度标注的范围为[1, 5], 标注间隔为0.5, 可用于离散或维度情感识别.
4.2 语音情感特征提取工具目前, 已有公开的程序或工具箱广泛应用于语音信号的处理、标注、频谱分析、特征提取等, 例如:PRAAT (http://www.fon.hum.uva.nl/praat)可实现对语音信号的采集、分析、标注、合成、统计分析等功能; OpenSMILE (http://audeering.com/research/opensmile/)软件对于音频处理的特征提取是一款很有效的工具, 是一种以命令行形式运行的而不是图形界面的操作软件, 通过配置config文件对音频进行特征提取; pyAudioAnalysis(an open-source python library for audio signal analysis, https://github.com/tyiannak/pyAudioAnalysis/wiki/2.-General)是Python下的一个音频处理工具包, 可用于音频特征提取; Librosa(https://librosa.github.io/)也是基于python的工具包, 可以提取各种语音特征, window和Linux均可; HTK Speech Recognition Toolkit(http://htk.eng.cam.ac.uk/)是基于C语言的特征提取工具包, 代码成熟稳定, 目前支持GPU, windows和Linux环境均可; Kaldi ASR (http://kaldi-asr.org/)是一个语音识别工具包, 开发效率高, Linux使用方便.
4.3 识别算法工具开源的深度学习神经网络正步入成熟, 目前有许多框架具备为语音情感识别提供先进的机器学习的能力.例如, TensorFlow(https://www.tensorflow.org/)是谷歌发布的开源工具, 编程接口支持Python和C++, 还可在谷歌云和亚马孙云中运行.TensorFlow支持细粒度的网格层, 而且允许用户在无需用低级语言实现的情况下构建新的复杂的层类型, 子图执行操作允许开发者在图的任意边缘引入和检索任意数据的结果.Caffe(http://caffe.berkeleyvision.org/)是自2013年底以来第一款主流的工业级深度学习工具包, 具有优秀的卷积模型, 是计算机视觉界最流行的工具包之一.CNTK(https://github.com/Microsoft/CNTK/wiki)是微软最初面向语音识别的框架, 支持RNN和CNN类型的网络模型, 从而在处理图像、手写字体和语音识别问题上, 它是很好的选择.MXNet (http://mxnet.io/)是一个全功能、可编程和可扩展的深度学习框架, 它支持深度学习架构, 如卷积神经网络(CNN)、循环神经网络(RNN)和其包含的长短时间记忆网络(LTSM), 为图像、手写文字和语音的识别和预测以及自然语言处理提供了出色的工具.PyTorch(http://pytorch.org/)是一种Python优先的深度学习框架, 特点是快速成形、代码可读和支持最广泛的深度学习模型.Theano(http://deeplearning.net/software/theano/)开创了将符号图用于神经网络编程的趋势, 但缺乏分布式应用程序管理框架, 只支持一种编程开发语言.
5 目前存在的问题及未来发展方向 5.1 计算模型缺乏脑科学、心理学等学科研究成果的指导现有的语音情感识别是基于计算机科学进行研究的, 利用机器学习的算法进行训练与识别.但情感是人类极其复杂的心理状态, 研究人类大脑的情感处理机制将尤为重要.目前, 情感识别的算法太简单, 缺乏心理学对情感研究成果的指导.如何更全面地建立情感的描述模型?不同情感之间是否有关联?例如, Ekman等人[150]的惊讶情感是对一件意料之外的事件的反应, 这种情感往往容易会跟随在高兴或者恐惧情感之后.Davidson[151]认为, 对惊讶情绪的识别需要考虑情境上下文.Banse等人[152]研究发现, 生气或者恐惧情绪的语音在声学特征上具有明显区分性, 也很少受到文化差异的影响, 更容易进行识别.
除此之外, 目前的情感识别框架缺乏人类大脑的复杂机制和工作模式的指导, 与认知功能之间的交互与协同较少.随着认知科学的快速发展, 科学家越来越多地了解人类大脑复杂的信息处理机制, 将这些成果与机器学习算法结合, 将有助于突破目前情感识别研究的瓶颈, 实现真正的人工智能.
5.2 语音情感数据标注困难语音情感类数据在收集与标注上存在的困难, 导致当下用于研究的数据规模较小, 种类较为贫乏.在上下文语境未知的情况下, 标注变得更加困难, 公认的有效、全面、优质的语音情感数据库是语音情感计算研究的基础.目前, 高质量的情感语料库很少, 而且缺乏大规模跨语言的公认语料库, 研究者们利用不同的数据库进行情感识别, 导致识别结果难以进行比较评价.目前, 用于情感标注的都是自我评价(self-report)方法, 如SAM量表等.研究者们可制定情感数据库标注的相关国标以明确详细的标注规则和方法; 借助数据标注公司、情感心理学专家的帮助, 建立拥有完整情感标注信息的优质语音情感数据库.
5.3 情感特征与语音情感之间存在鸿沟与离散情感识别类似, 进行维度情感识别的首要工作是特征提取, 决定了回归预测器准确率的高低.目前, 大多数特征是基于语音的声学特征, 这些声学特征能否有效地表征情感, 并没有详细的论证.情感特征的提取需要考虑两方面问题:首先, 所提取的声学特征与情感之间是否存在鸿沟, 能否有效地区分情感, 实现类内的特征距离较小、类间的特征距离较大; 其次, 情境上下文对情感的识别具有关键性作用, 需选取合适的时间粒度来提高情感识别率.
解决上述问题, 探索特征与情感类别之间映射关系, 提出对情感具有区分度的新特征, 将是非常有价值的研究方向.同时, 探索人类大脑对情感的处理机制, 结合心理学、认知学研究成果, 研究语音的各个层面(语素、词素、句法、语篇)对情感识别的影响.在此基础上, 提取不同粒度上的特征, 提高语音情感识别率.
5.4 用于维度情感识别的机器学习策略有待提高语音识别的快速发展得益于人工神经网络的支持, 特别是近年来深度神经网络的发展, 使语音识别性能进一步提升.研究者们往往借鉴语音识别中使用的神经网络模型进行情感识别, 但是情感是较语言更高层次的表达, 需要包含更多信息, 甚至推理、记忆、决策能力.因此, 目前用于情感识别的网络模型需要基于认知理论进一步改进, 探索人类情感处理机制, 并对认知模型进行实用化实现, 提出相应的机器学习方法, 进一步建立类脑多尺度神经网络计算模型以及类脑人工智能算法, 将是突破语音情感识别研究瓶颈的有效策略.
6 结束语语音情感识别是使机器实现自然的人机交互的重要方面, 不仅对推动信号处理、计算机、人工智能、人机交互、控制、认知等学科发展具有重要的学术意义, 而且具有重要的经济价值和社会意义, 如具有社交能力的情感机器人、情绪检测与监控、呼叫中心情绪考核等.基于情感的维度空间描述模型, 较传统的离散情感模型, 可以更精确地描述情感, 减小情感标签的模糊性, 具有无限的情感描述能力.基于维度情感模型的语音情感识别系统也日益受到越来越多的关注.相关研究人员已在语音情感认知、语音维度情感数据库、情感相关的语音特征提取以及识别算法方面取得长足的进步, 本文也主要针对这4个方面详细介绍了基于维度情感描述模型的语音情感识别进展, 填补了目前语音维度情感识别综述的空缺; 同时, 提出了该技术当前仍面临的一系列挑战, 如进一步探究人脑对语音情感认知规律、提出表征情感的语音特征、利用人脑情感认知机制指导识别算法的改进等.
| [1] |
Crystal, D. Non-segmental phonology in language acquisition:A review of the issues. Lingua, 1973, 32(1-2): 1-45.
https://www.sciencedirect.com/science/article/pii/0024384173900028 |
| [2] |
Liebenthal E, Silbersweig DA, Stern E. The language, tone and prosody of emotions: Neural substrates and dynamics of spoken-word emotion perception. Frontiers in Neuroscience, 2016, 10: No.506. https://pubmed.ncbi.nlm.nih.gov/27877106/
|
| [3] |
Murray IR, Arnott JL. Toward the simulation of emotion in synthetic speech:A review of the literature on human vocal emotion. The Journal of the Acoustical Society of America, 1993, 93(2): 1097-1108.
[doi:10.1121/1.405558] |
| [4] |
Williams CE, Stevens KN. Emotions and speech:Some acoustical correlates. The Journal of the Acoustical Society of America, 1972, 52(4B): 1238-1250.
[doi:10.1121/1.1913238] |
| [5] |
Murray IR, Arnott JL. Synthesizing emotions in speech: Is it time to get excited? In: Proc. of the 4th Int'l Conf. on Spoken Language Processing (ICSLP'96). IEEE, 1996. https://www.researchgate.net/publication/3703590_Synthesizing_emotions_in_speech_is_it_time_to_get_excited
|
| [6] |
Valstar M, Gratch J, Schuller B, et al. Depression, mood, and emotion recognition workshop and challenge. In: Proc. of the 6th Int'l Workshop on Audio/Visual Emotion Challenge (AVEC 2016). ACM, 2016. 3-10. https://www.researchgate.net/publication/301896305_AVEC_2016_-_Depression_Mood_and_Emotion_Recognition_Workshop_and_Challenge
|
| [7] |
Dhall A, Kaur A, Goecke R, Gedeon T. Emotiw 2018: Audio-video, student engagement and group-level affect prediction. In: Proc. of the 2018 on Int'l Conf. on Multimodal Interaction. ACM, 2018. https://www.researchgate.net/publication/327199917_EmotiW_2018_Audio-Video_Student_Engagement_and_Group-Level_Affect_Prediction
|
| [8] |
Li Y, Tao J, Schuller B, Shan S, Jiang D, Jia J. Mec 2016: The multimodal emotion recognition challenge of CCPR 2016. In: Proc. of the Chinese Conf. on Pattern Recognition. Springer-Verlag, 2016. https://link.springer.com/chapter/10.1007%2F978-981-10-3005-5_55
|
| [9] |
Li Y, Tao J, Schuller B, Shan S, Jiang D, Jia J. Mec 2017: Multimodal emotion recognition challenge. In: Proc. of the 20181st Asian Conf. on Affective Computing and Intelligent Interaction (ACII Asia). IEEE, 2018. https://www.researchgate.net/publication/329608457_MEC_2017_Multimodal_Emotion_Recognition_Challenge
|
| [10] |
Christianson SA. The Handbook of Emotion and Memory: Research and Theory. Psychology Press, 2014.
|
| [11] |
Lewis M, Haviland-Jones JM, Barrett LF. Handbook of Emotion. 3rd ed. The Guilford Press, 2008: 249-271.
|
| [12] |
Ortony A, Turner TJ. What's basic about basic emotions. Psychological Review, 1990, 97(3): 315-331.
|
| [13] |
Gunes H, Schuller B, Pantic M, Cowie R. Emotion representation, analysis and synthesis in continuous space: A survey. In: Proc. of the 2011 IEEE Int'l Conf. on Automatic Face & Gesture Recognition and Workshops (FG 2011). IEEE, 2011. https://www.researchgate.net/publication/224238109_Emotion_representation_analysis_and_synthesis_in_continuous_space_A_survey
|
| [14] |
Chen S, Jin Q. Multi-modal dimensional emotion recognition using recurrent neural networks. In: Proc. of the 5th Int'l Workshop on Audio/Visual Emotion Challenge. ACM, 2015. https://dl.acm.org/doi/10.1145/2808196.2811638
|
| [15] |
Ringeval F, Eyben F, Kroupi E, Yuce A, Thiran JP, Ebrahimi T, Lalanne D, Schuller B. Prediction of asynchronous dimensional emotion ratings from audiovisual and physiological data. Pattern Recognition Letters, 2015, 66: 22-30.
[doi:10.1016/j.patrec.2014.11.007] |
| [16] |
Fontaine J. The dimensional, basic, and componential emotion approaches to meaning in psychological emotion research. In: Proc. of the Components of Emotional Meaning: A Sourcebook. Oxford University Press, 2013. 31-45. https://www.researchgate.net/publication/281392075_Dimensional_basic_emotion_and_componential_approaches_to_meaning_in_psychological_emotion_research
|
| [17] |
Cowie R, Cornelius RR. Describing the emotional states that are expressed in speech. Speech Communication, 2003, 40(1-2): 5-32.
[doi:10.1016/S0167-6393(02)00071-7] |
| [18] |
Scherer KR. On the nature and function of emotion: A component process approach. In: Approaches to Emotion. Psychology Press, 1984.
|
| [19] |
Scherer KR. Vocal communication of emotion:A review of research paradigms. Speech Communication, 2003, 40(1-2): 227-256.
[doi:10.1016/S0167-6393(02)00084-5] |
| [20] |
Ortony A, Clore GL, Collins A. The Cognitive Structure of Emotions. Cambridge University Press, 1990.
|
| [21] |
Roseman IJ. Appraisal determinants of emotions:Constructing a more accurate and comprehensive theory. Cognition & Emotion, 1996, 10(3): 241-278.
https://www.tandfonline.com/doi/abs/10.1080/026999396380240 |
| [22] |
Soleimani A, Kobti Z. Toward a fuzzy approach for emotion generation dynamics based on occ emotion model. IAENG Int'l Journal of Computer Science, 2014, 41(1): 48-61.
https://www.researchgate.net/publication/288047035_Toward_a_Fuzzy_Approach_for_Emotion_Generation_Dynamics_Based_on_OCC_Emotion_Model |
| [23] |
Olgun ZN, Chae Y, Kim C. A system to generate robot emotional reaction for robot-human communication. In: Proc. of the 201815th Int'l Conf. on Ubiquitous Robots (UR). IEEE, 2018.
|
| [24] |
Masuyama N, Loo CK, Seera M. Personality affected robotic emotional model with associative memory for human-robot interaction. Neurocomputing, 2018, 272: 213-225.
[doi:10.1016/j.neucom.2017.06.069] |
| [25] |
Cavallo F, Semeraro F, Fiorini L, Magyar G, Sinčák P, Dario P. Emotion modelling for social robotics applications:A review. Journal of Bionic Engineering, 2018, 15(2): 185-203.
[doi:10.1007/s42235-018-0015-y] |
| [26] |
Rincon JA, Costa A, Novais P, Julian V, Carrascosa C. A new emotional robot assistant that facilitates human interaction and persuasion. In: Proc. of the Knowledge and Information Systems. 2018. 1-21. https://link.springer.com/article/10.1007/s10115-018-1231-9
|
| [27] |
Bartneck C, Lyons MJ, Saerbeck M. The relationship between emotion models and artificial intelligence. arXiv preprint arXiv: 1706.09554, 2017. https://www.researchgate.net/publication/200508159_The_Relationship_Between_Emotion_Models_and_Artificial_Intelligence
|
| [28] |
Wundt W. Vorlesungen über die Menschen-und Thierseele. The Monist, 1863.
|
| [29] |
Schlosberg H. Three dimensions of emotion. Psychological Review, 1954, 61(2): 81-88.
https://psycnet.apa.org/record/1954-08509-001 |
| [30] |
Russell JA, Mehrabian A. Evidence for a three-factor theory of emotions. Journal of Research in Personality, 1977, 11(3): 273-294.
[doi:10.1016/0092-6566(77)90037-X] |
| [31] |
Plutchik R. Emotions: A general psychoevolutionary theory. In: Approaches to Emotion. Psychology Press, 1984.
|
| [32] |
Russell JA. A circumplex model of affect. Journal of Personality and Social Psychology, 1980, 39(6): 1161-1178.
[doi:10.1037/h0077714] |
| [33] |
Krech D, Crutchfield RS, Livson N. Elements of Psychology. Alfred A. Knopf, 1974.
https://link.springer.com/chapter/10.1007%2F978-1-349-13113-6_1 |
| [34] |
Izard CE. The Psychology of Emotions. Springer Science & Business Media, 1991.
|
| [35] |
Mehrabian A. Analysis of the big-five personality factors in terms of the PAD temperament model. Australian Journal of Psychology, 1996, 48(2): 86-92.
[doi:10.1080/00049539608259510] |
| [36] |
Gebhard P. Alma: A layered model of affect. In: Proc. of the 4th Int'l Joint Conf. on Autonomous Agents and Multiagent Systems. ACM, 2005. https://www.researchgate.net/publication/221455945_ALMA_a_layered_model_of_affect
|
| [37] |
Becker-Asano C. Wasabi: Affect Simulation for Agents with Believable Interactivity. IOS Press, 2008.
|
| [38] |
Han WJ, Li HF, Ruan HB, Ma L. Review on speech emotion recognition. Ruan Jian Xue Bao/Journal of Software, 2014, 25(1): 37-50(in Chinese with English abstract).
http://www.jos.org.cn/1000-9825/4497.htm [doi:10.13328/j.cnki.jos.004497] |
| [39] |
MacLean PD. Psychosomatic disease and the "visceral brain"; Recent developments bearing on the Papez theory of emotion. Psychosomatic Medicine, 1949, 11(6): 338-353.
[doi:10.1097/00006842-194911000-00003] |
| [40] |
Arnold MB. Emotion and Personality. Columbia University Press, 1960.
|
| [41] |
Pribram KH. Feelings as monitors. In: Loyola Symp. on Feelings and Emotions. New York:Academic Press, 1970.
|
| [42] |
Lazarus RS, Folkman S. Stress, Appraisal, and Coping. Springer Publishing Company, 1984.
|
| [43] |
LeDoux J, Bemporad JR. The emotional brain. Journal of the American Academy of Psychoanalysis, 1997, 25(3): 525-528.
[doi:10.1521/jaap.1.1997.25.3.525] |
| [44] |
Morén J. Emotion and Learning-A Computational Model of the Amygdala[Ph.D. Thesis]. Lunds Universitet, 2002.
|
| [45] |
Morén J, Balkenius C. A computational model of emotional learning in the amygdala. From Animals to Animats, 2000, 6: 115-124.
https://core.ac.uk/display/20674540 |
| [46] |
Phelps EA, LeDoux JE. Contributions of the amygdala to emotion processing:From animal models to human behavior. Neuron, 2005, 48(2): 175-187.
[doi:10.1016/j.neuron.2005.09.025] |
| [47] |
Mathersul D, Williams LM, Hopkinson PJ, Kemp AH. Investigating models of affect:Relationships among EEG alpha asymmetry, depression, and anxiety. Emotion, 2008, 8(4): 560-572.
[doi:10.1037/a0012811] |
| [48] |
Chikazoe J, Lee DH, Kriegeskorte N, Anderson AK. Population coding of affect across stimuli, modalities and individuals. Nature Neuroscience, 2014, 17(8): 1114-1122.
[doi:10.1038/nn.3749] |
| [49] |
Kirkby LA, Luongo FJ, Lee MB, Nahum M, Van Vleet TM, Rao VR, Dawes HE, Chang EF, Sohal VS. An amygdala-hippocampus subnetwork that encodes variation in human mood. Cell, 2018, 175(6): 1688-1700.
[doi:10.1016/j.cell.2018.10.005] |
| [50] |
Lindquist KA, Wager TD, Kober H, Bliss-Moreau E, Barrett LF. The brain basis of emotion:A meta-analytic review. Behavioral and Brain Sciences, 2012, 35(3): 121-143.
[doi:10.1017/S0140525X11000446] |
| [51] |
Buchanan TW, Lutz K, Mirzazade S, Specht K, Shah NJ, Zilles K, Jäncke L. Recognition of emotional prosody and verbal components of spoken language:An fmri study. Cognitive Brain Research, 2000, 9(3): 227-238.
[doi:10.1016/S0926-6410(99)00060-9] |
| [52] |
George MS, Parekh PI, Rosinsky N, Ketter TA, Kimbrell TA, Heilman KM, Herscovitch P, Post RM. Understanding emotional prosody activates right hemisphere regions. Archives of Neurology, 1996, 53(7): 665-670.
[doi:10.1001/archneur.1996.00550070103017] |
| [53] |
Paulmann S, Kotz SA. Temporal interaction of emotional prosody and emotional semantics: Evidence from ERPs. In: Proc. of the Int'l Conf. on Speech Prosody. 2006. 89-92. https://www.researchgate.net/publication/38137930_Temporal_Interaction_of_Emotional_Prosody_and_Emotional_Semantics_Evidence_from_ERPs
|
| [54] |
Pihan H, Altenmüller E, Ackermann H. The cortical processing of perceived emotion:A DC-potential study on affective speech prosody. Neuroreport, 1997, 8(3): 623-627.
[doi:10.1097/00001756-199702100-00009] |
| [55] |
Ross ED, Thompson RD, Yenkosky J. Lateralization of affective prosody in brain and the callosal integration of hemispheric language functions. Brain and Language, 1997, 56(1): 27-54.
https://www.ncbi.nlm.nih.gov/pubmed/8994697 |
| [56] |
Ross ED, Edmondson JA, Seibert GB, Homan RW. Acoustic analysis of affective prosody during right-sided Wada test:A within-subjects verification of the right hemisphere's role in language. Brain and Language, 1988, 33(1): 128-145.
[doi:10.1016/0093-934X(88)90058-2] |
| [57] |
Davidson RJ, Abercrombie H, Nitschke JB, Putnam K. Regional brain function, emotion and disorders of emotion. Current Opinion in Neurobiology, 1999, 9(2): 228-234.
[doi:10.1016/S0959-4388(99)80032-4] |
| [58] |
Zatorre RJ, Belin P, Penhune VB. Structure and function of auditory cortex:Music and speech. Trends in Cognitive Sciences, 2002, 6(1): 37-46.
https://www.sciencedirect.com/science/article/pii/S1364661300018167 |
| [59] |
Ethofer T, Van De Ville D, Scherer K, Vuilleumier P. Decoding of emotional information in voice-sensitive cortices. Current Biology, 2009, 19(12): 1028-1033.
[doi:10.1016/j.cub.2009.04.054] |
| [60] |
Wildgruber D, Riecker A, Hertrich I, Erb M, Grodd W, Ethofer T, Ackermann H. Identification of emotional intonation evaluated by fMRI. Neuroimage, 2005, 24(4): 1233-1241.
[doi:10.1016/j.neuroimage.2004.10.034] |
| [61] |
Wildgruber D, Ackermann H, Kreifelts B, Ethofer T. Cerebral processing of linguistic and emotional prosody:Fmri studies. Progress in Brain Research, 2006, 156: 249-268.
[doi:10.1016/S0079-6123(06)56013-3] |
| [62] |
Grandjean D, Sander D, Pourtois G, Schwartz S, Seghier ML, Scherer KR, Vuilleumier P. The voices of wrath:Brain responses to angry prosody in meaningless speech. Nature Neuroscience, 2005, 8(2): 145-146.
https://www.ncbi.nlm.nih.gov/pubmed/15665880 |
| [63] |
Kotz SA, Kalberlah C, Bahlmann J, Friederici AD, Haynes JD. Predicting vocal emotion expressions from the human brain. Human Brain Mapping, 2013, 34(8): 1971-1981.
[doi:10.1002/hbm.22041] |
| [64] |
Fritsch N, Kuchinke L. Acquired affective associations induce emotion effects in word recognition:An ERP study. Brain and Language, 2013, 124(1): 75-83.
https://www.sciencedirect.com/science/article/abs/pii/S0093934X12002167 |
| [65] |
Elliot C. The affective reasoner: A process model of emotions in a multi-agent system[Ph.D. Thesis]. Northwestern University, 1992.
|
| [66] |
Reilly WS. Believable social and emotional agents[Ph.D. Thesis]. Carnegie-Mellon University, 1996. https://www.researchgate.net/publication/2668281_Believable_Social_and_Emotional_Agents
|
| [67] |
Gratch J, Marsella S. Evaluating the modeling and use of emotion in virtual humans. In: Proc. of the 3rd Int'l Joint Conf. on Autonomous Agents and Multiagent Systems, Vol.1. IEEE Computer Society, 2004. 320-327. https://www.researchgate.net/publication/4112094_Evaluating_the_modeling_and_use_of_emotion_in_virtual_humans
|
| [68] |
Velásquez JD, Maes P. Cathexis: A computational model of emotions. In: Proc. of the 1st Int'l Conf. on Autonomous Agents. ACM, 1997. 93-98. https://www.researchgate.net/publication/220794053_Cathexis_A_Computational_Model_of_Emotions
|
| [69] |
Marsella S, Gratch J, Petta P. Computational models of emotion. A Blueprint for Affective Computing-A Sourcebook and Manual, 2010, 11(1): 21-46.
https://www.researchgate.net/publication/313596990_Computational_models_of_emotion |
| [70] |
Watts L. Reverse-engineering the human auditory pathway. In: Proc. of the Advances in Computational Intelligence. Springer-Verlag, 2012. 47-59.
|
| [71] |
Abdi J, Moshiri B, Abdulhai B, Sedigh AK. Forecasting of short-term traffic-flow based on improved neurofuzzy models via emotional temporal difference learning algorithm. Engineering Applications of Artificial Intelligence, 2012, 25(5): 1022-1042.
[doi:10.1016/j.engappai.2011.09.011] |
| [72] |
Falahiazar A, Setayeshi S, Sharafi Y. Computational model of social intelligence based on emotional learning in the amygdala. Journal of Mathematics and Computer Science, 2015, 14: 77-86.
[doi:10.22436/jmcs.014.01.08] |
| [73] |
Milad HS, Farooq U, El-Hawary ME, Asad MU. Neo-fuzzy integrated adaptive decayed brain emotional learning network for online time series prediction. IEEE Access, 2017, 5: 1037-1049.
[doi:10.1109/ACCESS.2016.2637381] |
| [74] |
Lotfi E, Khazaei O, Khazaei F. Competitive brain emotional learning. Neural Processing Letters, 2018, 47(2): 745-764.
https://www.researchgate.net/publication/319053212_Competitive_Brain_Emotional_Learning |
| [75] |
Lucas C, Shahmirzadi D, Sheikholeslami N. Introducing BELBIC:Brain emotional learning based intelligent controller. Intelligent Automation & Soft Computing, 2004, 10(1): 11-21.
https://www.tandfonline.com/doi/abs/10.1080/10798587.2004.10642862 |
| [76] |
Parsapoor M, Bilstrup U. Brain emotional learning based fuzzy inference system (BELFIS) for solar activity forecasting. In: Proc. of the IEEE 24th Int'l Conf. on Tools with Artificial Intelligence. IEEE, 2012. 532-539.
|
| [77] |
Motamed S, Setayeshi S, Rabiee A. Speech emotion recognition based on a modified brain emotional learning model. Biologically Inspired Cognitive Architectures, 2017, 19: 32-38.
[doi:10.1016/j.bica.2016.12.002] |
| [78] |
Grimm M, Kroschel K, Mower E, Narayanan S. Primitives-based evaluation and estimation of emotions in speech. Speech Communication, 2007, 49(10-11): 787-800.
[doi:10.1016/j.specom.2007.01.010] |
| [79] |
Hammerschmidt K, Jürgens U. Acoustical correlates of affective prosody. Journal of Voice, 2007, 21(5): 531-540.
[doi:10.1016/j.jvoice.2006.03.002] |
| [80] |
Laukka P, Elfenbein HA, Söder N, Nordström H, Althoff J, Iraki FKE, Rockstuhl T, Thingujam NS. Cross-cultural decoding of positive and negative non-linguistic emotion vocalizations. Frontiers in Psychology, 2013, 4: No.353.
|
| [81] |
Sauter DA, Eisner F, Ekman P, et al. Cross-cultural recognition of basic emotions through nonverbal emotional vocalizations. Proc. of the National Academy of Sciences, 2010, 107(6): 2408-2412.
[doi:10.1073/pnas.0908239106] |
| [82] |
Tickle A. English and Japanese speakers' emotion vocalisation and recognition: A comparison highlighting vowel quality. In: Proc. of the ISCA Tutorial and Research Workshop (ITRW) on Speech and Emotion. 2000. https://www.researchgate.net/publication/253504281_ENGLISH_AND_JAPANESE_SPEAKERS'_EMOTION_VOCALISATION_AND_RECOGNITION_A_COMPARISON_HIGHLIGHTING_VOWEL_QUALITY
|
| [83] |
Yang LC, Campbell N. Linking form to meaning: The expression and recognition of emotions through prosody. In: Proc. of the 4th ISCA Tutorial and Research Workshop (ITRW) on Speech Synthesis. 2001. https://www.researchgate.net/publication/228356677_Linking_form_to_meaning_The_expression_and_recognition_of_emotions_through_prosody
|
| [84] |
Thompson WF, Balkwill LL. Decoding speech prosody in five languages. Semiotica, 2006, 2006(158): 407-424.
http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=10.1515/SEM.2006.017 |
| [85] |
Pell MD, Monetta L, Paulmann S, Kotz SA. Recognizing emotions in a foreign language. Journal of Nonverbal Behavior, 2009, 33(2): 107-120.
[doi:10.1007/s10919-008-0065-7] |
| [86] |
Bryant G, Barrett HC. Vocal emotion recognition across disparate cultures. Journal of Cognition and Culture, 2008, 8(1-2): 135-148.
[doi:10.1163/156770908X289242] |
| [87] |
Émond C, Ménard L, Laforest M, Bimbot F, Cerisara C, Fougeron C, Gravier G, Lamel L. Perceived prosodic correlates of smiled speech in spontaneous data. In: Proc. of the Interspeech. 2013. https://www.researchgate.net/publication/287777067_Perceived_prosodic_correlates_of_smiled_speech_in_spontaneous_data
|
| [88] |
Wang YT, Han J, Jiang XQ, Zou J, Zhao H. Study of speech emotion recognition based on prosodic parameters and facial expression features. In: Proc. of the Applied Mechanics and Materials. 2013. https://www.researchgate.net/publication/258587635_Study_of_Speech_Emotion_Recognition_Based_on_Prosodic_Parameters_and_Facial_Expression_Features
|
| [89] |
Rao KS, Koolagudi SG, Vempada RR. Emotion recognition from speech using global and local prosodic features. Int'l Journal of Speech Technology, 2013, 16(2): 143-160.
[doi:10.1007/s10772-012-9172-2] |
| [90] |
Pao TL, Chen YT, Yeh JH, Liao WY. Detecting emotions in mandarin speech. Int'l Journal of Computational Linguistics & Chinese Language Processing, 2005, 10(3): 347-362.
http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=J-STAGE_2188686 |
| [91] |
Pereira C. Dimensions of emotional meaning in speech. In: Proc. of the ISCA Tutorial and Research Workshop (ITRW) on Speech and Emotion. 2000. https://www.researchgate.net/publication/2328489_Dimensions_Of_Emotional_Meaning_In_Speech
|
| [92] |
Borchert M, Dusterhoft A. Emotions in speech-experiments with prosody and quality features in speech for use in categorical and dimensional emotion recognition environments. In: Proc. of the 2005 Int'l Conf. on Natural Language Processing and Knowledge Engineering. IEEE, 2005.
|
| [93] |
Arias JP, Busso C, Yoma NB. Shape-based modeling of the fundamental frequency contour for emotion detection in speech. Computer Speech & Language, 2014, 28(1): 278-294.
http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=31d5b2b1503bb3038b536ddb4b1c8d78 |
| [94] |
Cowie R, Douglas-Cowie E, Tsapatsoulis N, Votsis G, Kollias S, Fellenz W, Taylor JG. Emotion recognition in human-computer interaction. IEEE Signal Processing Magazine, 2001, 18(1): 32-80.
https://www.researchgate.net/publication/3321357_Emotion_recognition_in_human-computer_interaction |
| [95] |
Sant'Ana R, Coelho R, Alcaim A. Text-independent speaker recognition based on the Hurst parameter and the multidimensional fractional Brownian motion model. IEEE Trans. on Audio, Speech, and Language Processing, 2006, 14(3): 931-940.
[doi:10.1109/TSA.2005.858054] |
| [96] |
Zao L, Cavalcante D, Coelho R. Time-frequency feature and AMS-GMM mask for acoustic emotion classification. IEEE Signal Processing Letters, 2014, 21(5): 620-624.
[doi:10.1109/LSP.2014.2311435] |
| [97] |
Mencattini A, Martinelli E, Costantini G, Todisco M, Basile B, Bozzali M, Di Natale C. Speech emotion recognition using amplitude modulation parameters and a combined feature selection procedure. Knowledge-based Systems, 2014, 63: 68-81.
[doi:10.1016/j.knosys.2014.03.019] |
| [98] |
Tato R, Santos R, Kompe R, Pardo JM. Emotional space improves emotion recognition. In: Proc. of the 7th Int'l Conf. on Spoken Language Processing. 2002.
|
| [99] |
Idris I, Salam MSH. Emotion detection with hybrid voice quality and prosodic features using neural network. In: Proc. of the 20144th World Congress on Information and Communication Technologies (WICT 2014). IEEE, 2014. https://www.researchgate.net/publication/282823710_Emotion_detection_with_hybrid_voice_quality_and_prosodic_features_using_Neural_Network
|
| [100] |
Kächele M, Zharkov D, Meudt S, Schwenker F. Prosodic, spectral and voice quality feature selection using a long-term stopping criterion for audio-based emotion recognition. In: Proc. of the 201422nd Int'l Conf. on Pattern Recognition. IEEE, 2014. https://www.researchgate.net/publication/286680123_Prosodic_Spectral_and_Voice_Quality_Feature_Selection_Using_a_Long-Term_Stopping_Criterion_for_Audio-Based_Emotion_Recognition
|
| [101] |
Huang Y, Zhang G, Li Y, Wu A. Improved emotion recognition with novel task-oriented wavelet packet features. In: Proc. of the Int'l Conf. on Intelligent Computing. Springer-Verlag, 2014.
|
| [102] |
Ziółko M, Jaciów P, Igras M. Combination of Fourier and wavelet transformations for detection of speech emotions. In: Proc. of the 20147th Int'l Conf. on Human System Interactions (HSI). IEEE, 2014. https://www.researchgate.net/publication/265292980_Combination_of_Fourier_and_wavelet_transformations_for_detection_of_speech_emotions
|
| [103] |
Idris I, Salam MS. Improved speech emotion classification from spectral coefficient optimization. In: Proc. of the Advances in Machine Learning and Signal Processing. Springer-Verlag, 2016. 247-257.
|
| [104] |
Espinosa HP, García CAR, Pineda LV. Features selection for primitives estimation on emotional speech. In: Proc. of the 2010 IEEE Int'l Conf. on Acoustics, Speech and Signal Processing. IEEE, 2010.
|
| [105] |
Wang K, An N, Li BN, Zhang Y, Li L. Speech emotion recognition using fourier parameters. IEEE Trans. on Affective Computing, 2015, 6(1): 69-75.
[doi:10.1109/TAFFC.2015.2392101] |
| [106] |
Ghosh S, Laksana E, Morency LP, Scherer S. Representation learning for speech emotion recognition. In: Proc. of the Interspeech. 2016. https://www.researchgate.net/publication/307889274_Representation_Learning_for_Speech_Emotion_Recognition
|
| [107] |
Schuller B, Rigoll G. Recognising interest in conversational speech-comparing bag of frames and supra-segmental features. In: Proc. of the Interspeech 2009. Brighton, 2009. https://www.researchgate.net/publication/221486128_Recognising_interest_in_conversational_speech_-_Comparing_bag_of_frames_and_supra-segmental_features
|
| [108] |
El Ayadi M, Kamel MS, Karray F. Survey on speech emotion recognition:Features, classification schemes, and databases. Pattern Recognition, 2011, 44(3): 572-587.
[doi:10.1016/j.patcog.2010.09.020] |
| [109] |
Origlia A, Cutugno F, Galatà V. Continuous emotion recognition with phonetic syllables. Speech Communication, 2014, 57: 155-169.
[doi:10.1016/j.specom.2013.09.012] |
| [110] |
Sethu V, Ambikairajah E, Epps J. On the use of speech parameter contours for emotion recognition. EURASIP Journal on Audio, Speech, and Music Processing, 2013, 2013(1): No.19.
|
| [111] |
Han WJ, Li HF, Han JQ. Speech emotion recognition with combined short and long term features. Journal of Tsinghua University (Science and Technology), 2008, 48(1): 708-714(in Chinese with English abstract).
http://www.cnki.com.cn/Article/CJFDTotal-QHXB2008S1017.htm |
| [112] |
Chen J, Li HF, Ma L, Chen X, Chen XM. Multi-granularity feature fusion for dimensional speech emotion recognition. Journal of Signal Processing, 2017, 33(3): 374-382(in Chinese with English abstract).
http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=xhcl201703018 |
| [113] |
Deng J, Cummins N, Han J, Xu X, Ren Z, Pandit V, Zhang Z, Schuller B. The university of Passau open emotion recognition system for the multimodal emotion challenge. In: Proc. of the Chinese Conf. on Pattern Recognition. Springer-Verlag, 2016. https://link.springer.com/chapter/10.1007%2F978-981-10-3005-5_54
|
| [114] |
Lee CM, Narayanan SS. Toward detecting emotions in spoken dialogs. IEEE Trans. on Speech and Audio Processing, 2005, 13(2): 293-303.
[doi:10.1109/TSA.2004.838534] |
| [115] |
Schuller B, Rigoll G, Lang M. Speech emotion recognition combining acoustic features and linguistic information in a hybrid support vector machine-belief network architecture. In: Proc. of the 2004 IEEE Int'l Conf. on Acoustics, Speech, and Signal Processing. IEEE, 2004.
|
| [116] |
Wu CH, Liang WB. Emotion recognition of affective speech based on multiple classifiers using acoustic-prosodic information and semantic labels. IEEE Trans. on Affective Computing, 2011, 2(1): 10-21.
[doi:10.1109/T-AFFC.2010.16] |
| [117] |
Wold S, Sjöström M, Eriksson L. PLS-regression:A basic tool of chemometrics. Chemometrics and Intelligent Laboratory Systems, 2001, 58(2): 109-130.
[doi:10.1016/S0169-7439(01)00155-1] |
| [118] |
Vinzi VE, Trinchera L, Amato S. PLS Path Modeling:From Foundations to Recent Developments and Open Issues for Model Assessment and Improvement. Handbook of Partial Least Squares. Springer-Verlag, 2010, 47-82.
https://www.academia.edu/224551/PLS_Path_Modeling_From_Foundations_to_Recent_Developments_and_Open_Issues_for_Model_Assessment_and_Improvement |
| [119] |
Vapnik V. The Nature of Statistical Learning Theory. Springer Science & Business Media, 2013.
https://link.springer.com/book/10.1007%2F978-1-4757-3264-1 |
| [120] |
Campbell C. An introduction to kernel methods. Studies in Fuzziness and Soft Computing, 2001, 66: 155-192.
[doi:10.1109/72.914517] |
| [121] |
Smola AJ, Schölkopf B. A tutorial on support vector regression. Statistics and Computing, 2004, 14(3): 199-222.
[doi:10.1023/B:STCO.0000035301.49549.88] |
| [122] |
Grimm M, Kroschel K, Narayanan S. Support vector regression for automatic recognition of spontaneous emotions in speech. In: Proc. of the 2007 IEEE Int'l Conf. on Acoustics, Speech and Signal Processing (ICASSP 2007). IEEE, 2007.
|
| [123] |
Giannakopoulos T, Pikrakis A, Theodoridis S. A dimensional approach to emotion recognition of speech from movies. In: Proc. of the 2009 IEEE Int'l Conf. on Acoustics, Speech and Signal Processing. IEEE, 2009.
|
| [124] |
Kanluan I, Grimm M, Kroschel K. Audio-visual emotion recognition using an emotion space concept. In: Proc. of the 200816th European Signal Processing Conf. IEEE, 2008.
|
| [125] |
Wöllmer M, Kaiser M, Eyben F, Schuller B, Rigoll G. LSTM-modeling of continuous emotions in an audiovisual affect recognition framework. Image and Vision Computing, 2013, 31(2): 153-163.
[doi:10.1016/j.imavis.2012.03.001] |
| [126] |
Schuller B, Valstar M, Eyben F, McKeown G, Cowie R, Pantic M. AVEC 2011-The 1st Int'l audio/visual emotion challenge. In: Proc. of the Int'l Conf. on Affective Computing and Intelligent Interaction. Springer-Verlag, 2011.
|
| [127] |
Chao L, Tao J, Yang M, Li Y, Wen Z. Long short term memory recurrent neural network based multimodal dimensional emotion recognition. In: Proc. of the 5th Int'l Workshop on Audio/Visual Emotion Challenge. ACM, 2015. https://www.researchgate.net/publication/301422418_Long_Short_Term_Memory_Recurrent_Neural_Network_based_Multimodal_Dimensional_Emotion_Recognition
|
| [128] |
Chen YL, Cheng YF, Chen XQ, Wang HX, Li C. Speech emotion estimation in PAD 3D emotion space. Journal of Harbin Institute of Technology, 2018, 50(11): 160-166(in Chinese with English abstract).
[doi:10.11918/j.issn.0367-6234.201806131] |
| [129] |
Han WJ, Li HF, Ma L. Considering relative order of emotional degree in dimensional speech emotion recognition. Signal Processing, 2011, 27(11): 1658-1663(in Chinese with English abstract).
[doi:10.3969/j.issn.1003-0530.2011.11.005] |
| [130] |
Tanaka A, Koizumi A, Imai H, Hiramatsu S, Hiramoto E, de Gelder B. I feel your voice:Cultural differences in the multisensory perception of emotion. Psychological Science, 2010, 21(9): 1259-1262.
[doi:10.1177/0956797610380698] |
| [131] |
Liu P, Rigoulot S, Pell MD. Culture modulates the brain response to human expressions of emotion:Electrophysiological evidence. Neuropsychologia, 2015, 67: 1-13.
[doi:10.1016/j.neuropsychologia.2014.11.034] |
| [132] |
Liu P, Rigoulot S, Pell MD. Cultural differences in on-line sensitivity to emotional voices: Comparing east and west. Frontiers in Human Neuroscience, 2015, 9: No.311. 10.3389/fnhum.2015.00311
|
| [133] |
Elfenbein HA, Ambady N. On the universality and cultural specificity of emotion recognition:A meta-analysis. Psychological Bulletin, 2002, 128(2): 203-235.
[doi:10.1037/0033-2909.128.2.203] |
| [134] |
Song P. Transfer linear subspace learning for cross-corpus speech emotion recognition. IEEE Annals of the History of Computing, 2019(2): 265-275.
http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=943e589b1552a7cfaaec54a90f305201 |
| [135] |
Sagha H, Matejka P, Gavryukova M, Povolný F, Marchi E, Schuller BW. Enhancing multilingual recognition of emotion in speech by language identification. In: Proc. of the Interspeech. 2016. https://www.researchgate.net/publication/303882230_Enhancing_Multilingual_Recognition_of_Emotion_in_Speech_by_Language_Identification
|
| [136] |
Kaya H, Karpov AA. Efficient and effective strategies for cross-corpus acoustic emotion recognition. Neurocomputing, 2018, 275: 1028-1034.
[doi:10.1016/j.neucom.2017.09.049] |
| [137] |
Feraru SM, Schuller D. Cross-language acoustic emotion recognition: An overview and some tendencies. In: Proc. of the 2015 Int'l Conf. on Affective Computing and Intelligent Interaction (ACII). IEEE, 2015. https://www.researchgate.net/publication/308728596_Cross-language_acoustic_emotion_recognition_An_overview_and_some_tendencies
|
| [138] |
Böck R, Siegert I, Haase M, Lange J, Wendemuth A. Ikannotate-A tool for labelling, transcription, and annotation of emotionally coloured speech. In: Proc. of the Int'l Conf. on Affective Computing and Intelligent Interaction. Springer, 2011.
|
| [139] |
Cowie R, Douglas-Cowie E, Savvidou S, McMahon E, Sawey M, Schröder M. 'Feeltrace': An instrument for recording perceived emotion in real time. In: Proc. of the ISCA Tutorial and Research Workshop (ITRW) on Speech and Emotion. 2000. 19-24. https://www.researchgate.net/publication/209436026_%27FEELTRACE%27_An_instrument_for_recording_perceived_emotion_in_real_time
|
| [140] |
Zenk R, Franz M, Bubb H. Emocard-An approach to bring more emotion in the comfort concept. SAE Int'l Journal of Passenger Cars-mechanical Systems, 2008, 1: 775-782.
[doi:10.4271/2008-01-0890] |
| [141] |
Bradley MM, Lang PJ. Measuring emotion:The self-assessment manikin and the semantic differential. Journal of Behavior Therapy and Experimental Psychiatry, 1994, 25(1): 49-59.
[doi:10.1016/0005-7916(94)90063-9] |
| [142] |
Lang PJ. Int'l affective picture system (IAPS): Affective ratings of pictures and instruction manual. Technical Report, University of Florida, 2005.
|
| [143] |
Broekens J, Brinkman WP. AffectButton:A method for reliable and valid affective self-report. Int'l Journal of Human-computer Studies, 2013, 71(6): 641-667.
[doi:10.1016/j.ijhcs.2013.02.003] |
| [144] |
Ringeval F, Sonderegger A, Sauer J, Lalanne D. Introducing the RECOLA multimodal corpus of remote collaborative and affective interactions. In: Proc. of the 201310th IEEE Int'l Conf. and Workshops on Automatic Face and Gesture Recognition (FG). IEEE, 2013.
|
| [145] |
Siegert I, Wendemuth A. Ikannotate2-A tool supporting annotation of emotions in audio-visual data. Studientexte Zur Sprachkommunikation:Elektronische Sprach Signal Verarbeitung, 2017, 17-24.
http://www.researchgate.net/publication/315456689_ikannotate2_-_A_Tool_Supporting_Annotation_of_Emotions_in_Audio-Visual_Data |
| [146] |
Grimm M, Kroschel K, Narayanan S. The Vera ammittag german audio-visual emotional speech database. In: Proc. of the 2008 IEEE Int'l Conf. on Multimedia and Expo. IEEE, 2008. https://www.researchgate.net/publication/221262340_The_Vera_am_Mittag_German_audio-visual_emotional_speech_database
|
| [147] |
McKeown G, Valstar MF, Cowie R, Pantic M. The SEMAINE corpus of emotionally coloured character interactions. In: Proc. of the 2010 IEEE Int'l Conf. on Multimedia and Expo. IEEE, 2010. https://www.researchgate.net/publication/221266405_The_SEMAINE_corpus_of_emotionally_coloured_character_interactions
|
| [148] |
Schuller B, Valster M, Eyben F, Cowie R, Pantic M. AVEC 2012: The continuous audio/visual emotion challenge. In: Proc. of the 14th ACM Int'l Conf. on Multimodal Interaction. ACM, 2012. https://www.researchgate.net/publication/224929613_AVEC_2012_--_The_Continuous_AudioVisual_Emotion_Challenge
|
| [149] |
Busso C, Bulut M, Lee CC, Kazemzadeh A, Mower E, Kim S, Chang JN, Lee S, Narayanan SS. IEMOCAP:Interactive emotional dyadic motion capture database. Language Resources and Evaluation, 2008, 42(4): 335-359.
[doi:10.1007/s10579-008-9076-6] |
| [150] |
Ekman P, Friesen WV. Measuring facial movement. Environmental Psychology and Nonverbal Behavior, 1976, 1(1): 56-75.
[doi:10.1007/BF01115465] |
| [151] |
Davidson RJ. Affective style, psychopathology, and resilience:Brain mechanisms and plasticity. American Psychologist, 2000, 55(11): 1196-1214.
[doi:10.1037/0003-066X.55.11.1196] |
| [152] |
Banse R, Scherer KR. Acoustic profiles in vocal emotion expression. Journal of Personality and Social Psychology, 1996, 70(3): 614-636.
[doi:10.1037/0022-3514.70.3.614] |
| [38] |
韩文静, 李海峰, 阮华斌, 马琳. 语音情感识别研究进展综述. 软件学报, 2014, 25(1): 37-50.
http://www.jos.org.cn/1000-9825/4497.htm [doi:10.13328/j.cnki.jos.004497] |
| [111] |
韩文静, 李海峰, 韩纪庆. 基于长短时特征融合的语音情感识别方法. 清华大学学报:自然科学版, 2008, 48(1): 708-714.
http://www.cnki.com.cn/Article/CJFDTotal-QHXB2008S1017.htm |
| [112] |
陈婧, 李海峰, 马琳, 陈肖, 陈晓敏. 多粒度特征融合的维度语音情感识别方法. 信号处理, 2017, 33(3): 374-382.
http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=xhcl201703018 |
| [128] |
陈逸灵, 程艳芬, 陈先桥, 王红霞, 李超. PAD三维情感空间中的语音情感识别. 哈尔滨工业大学学报, 2018, 50(11): 160-166.
[doi:10.11918/j.issn.0367-6234.201806131] |
| [129] |
韩文静, 李海峰, 马琳. 考虑情感程度相对顺序的维度语音情感识别. 信号处理, 2011, 27(11): 1658-1663.
[doi:10.3969/j.issn.1003-0530.2011.11.005] |